向量处理机
向量处理机
真题
简答题·全
简述 CRAY-1 向量处理机 $V_i$ 冲突和功能部件冲突的概念 2204
简述阵列处理机与流水处理机相比的特点、区别 1410 2010 x2
简述 SIMD 系统互连网络的设计目标 1304 1604
简述多级立方体网络对各个交换开关的控制方式 2110
简述实现全排列网络的两种方法 2008
简述脉动阵列结构的特点 1504 1910 **
应用题·全
向量链接技术 ** *






蝶式交换和Omega网络 ** **


PM2I网络

多级立方体网络(Cube)

答:如果是 STARAN 网络,无法实现上述 5 对同时进行传送,因为该网络采用的是级控制,同一级只能是一种开关状态。

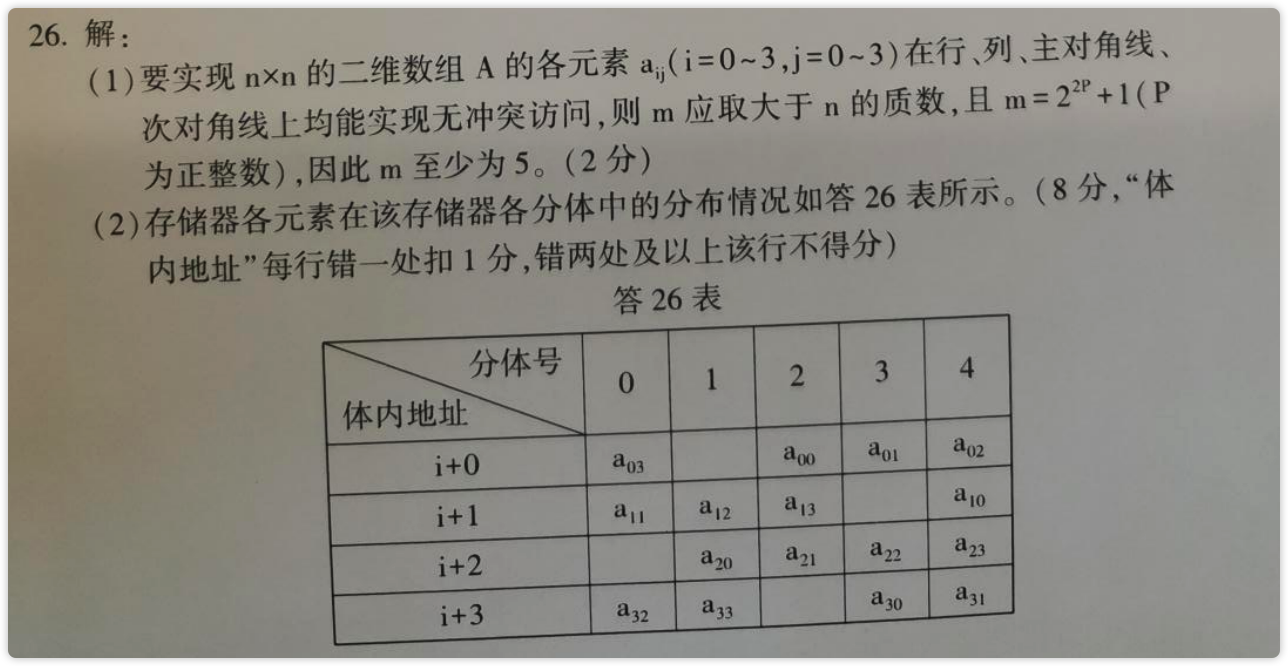
共享主存构形的阵列处理机中并行存储器的无冲突访问 **

存储分体个数 K ≥ 处理单元数 N




向量处理机
具有向量数据表示和向量指令系统的处理机,分向量流水处理机和阵列处理机。其中向量流水处理机是以时间重叠途径开发,阵列处理机是以资源重复途径开发。^
关于向量处理机你要知道:
- 是用于解决数值计算问题的高性能计算机
- 属于大型或巨型机,但也可以通过微机+向量协处理机组成
- 向一般采用流水线结构,并以多条流水线并行的方式工作
- 只有把待解决的问题转化为向量运算,才可发挥向量机的效率
应试要求
要求:理解什么是向量的流水处理,通过向量指令的并行和链接提高性能,阵列处理机的工作原理和结构,了解流水处理机与阵列处理机的差异;理解阵列处理机对并行算法、存储单元分配、互连网络的要求;熟练掌握基本单级互连网络的互连函数表示;理解循环互连网络的实现;熟练掌握多级网络、全排列网络的画法;理解共享主存构形的阵列处理机解决并行存储器无冲突访问的办法;理解脉动阵列流水处理机的原理和通用结构。
本章的重点是:向量流水处理机中向量指令间的并行、链接,阵列处理机互连网络、互连函数、至级互连网络。难点是:向量处理机的向量指令间的并行、 链接,完成全部指令的时钟拍数计算,阵列处理机的并行算法和多级互连网络。
向量流水处理机
向量的处理方式
结论先行,向量横向处理是向量的处理方式,但不是向量的流水处理方式;而向量纵向处理和分组纵横处理既是向量的处理方式,也是向量的流水处理方式。
- 横向处理,计算时,按行从左至右横向进行。
- 纵向处理,计算时,按列从上往下纵向进行
- 纵横处理,计算时,行列结合同时进行。
【例】
for(i=1;i<=n;i++){ y[i] = a[i] * (b[i] + c[i]); }横向处理上述代码:
计算第1个分量:temp[1]=b[1]+c[1]; y[1]=a[1]*temp[1]; 计算第2个分量:temp[2]=b[2]+c[2]; y[2]=a[2]*temp[2]; ··· ··· 计算第n个分量:temp[n]=b[n]+c[n]; y[n]=a[n]*temp[n];横向处理存在2个问题:
- 计算每一个分量时,都会发送写读数据相关。
- 若采用多功能流水线,会发送频繁的流水线切换
纵向处理上述代码:
temp[1]=b[1]+c[1] temp[2]=b[2]+c[2] ··· ··· temp[n]=b[n]+c[n] y[1]=a[1]*temp[1] y[2]=a[2]*temp[2] ··· ··· y[n]=a[n]*temp[n]纵向处理时,只会用到2条向量指令:
VADD b,c,temp VMUL a,temp,y每条向量指令仅做单一相同的运算,两条向量指令之间仅有1次功能切换,适用于向量处理机。采用链接技术,可以使数据相关不影响流水线的进行。但纵向处理对存储器的信息流量要求较高,因为向量指令的源向量和目标向量都是放在存储器中,运算的中间结果也需送回到存储器中进行保存。
纵横处理上述代码
按如下方式分组:(1,n)(n+1,2n)(2n+1,3n)···(kn+1,kn)
第1组: temp[1,n]=b[1,n]+c[1,n] y[1,n]=a[1,n]*temp[1,n] 第2组: tem[n+1,2n]=b[n+1,2n]+c[n+1,2n] y[n+1,2n]=a[n+1,2n]*temp[1,2n] ··· ···纵横方式采取的是组内纵向,组间横向,可以减少访存次数,提高处理速度。
通过并行、链接提高性能 *
向量指令
以 $CRAY-1$ 向量处理机为例,其有4类指令(2种指令格式):
- 向量与向量操作: $V_i \quad ← \quad V_j \quad OP \quad V_k$
- 向量与标量操作:$V_i \quad ← \quad S_j \quad OP \quad V_k$
- 向量取:$V_i \quad ← \quad 存储器 $
- 向量存:$存储器 \quad ← \quad V_i $
【图】向量运算中的数据相关和功能部件冲突 * ^
image-20230225122115550 $V_i$ 冲突:并行工作的各向量指令的源向量或结果向量同时使用了相同的 $V_i$ ,如图(b)和图(d)。
功能部件冲突:并行工作的各向量指令同时使用了相同的功能部件,如图(c)。

链接技术
当前一条指令的结果寄存器可以作为后续指令的操作数寄存器时,多条有数据相关的向量指令并行执行,这种技术称为两条流水线的链接技术。这种方式能够保证前面功能部件的结果元素一经产生,就可以立即被后面的功能部件使用,而无需等结果向量全部产生后再使用。
向量链接技术的应用是有一些基本要求的,以 CRAY-1 为例,其有一个显著的特点是只要不出现功能部件使用冲突和源向量寄存器使用冲突,就能够通过链接技术使有数据相关的指令并行执行。
【例】可链接执行的场景 *
image-20230225122841885 image-20230225123403341 image-20230225123428964 image-20230225123654146

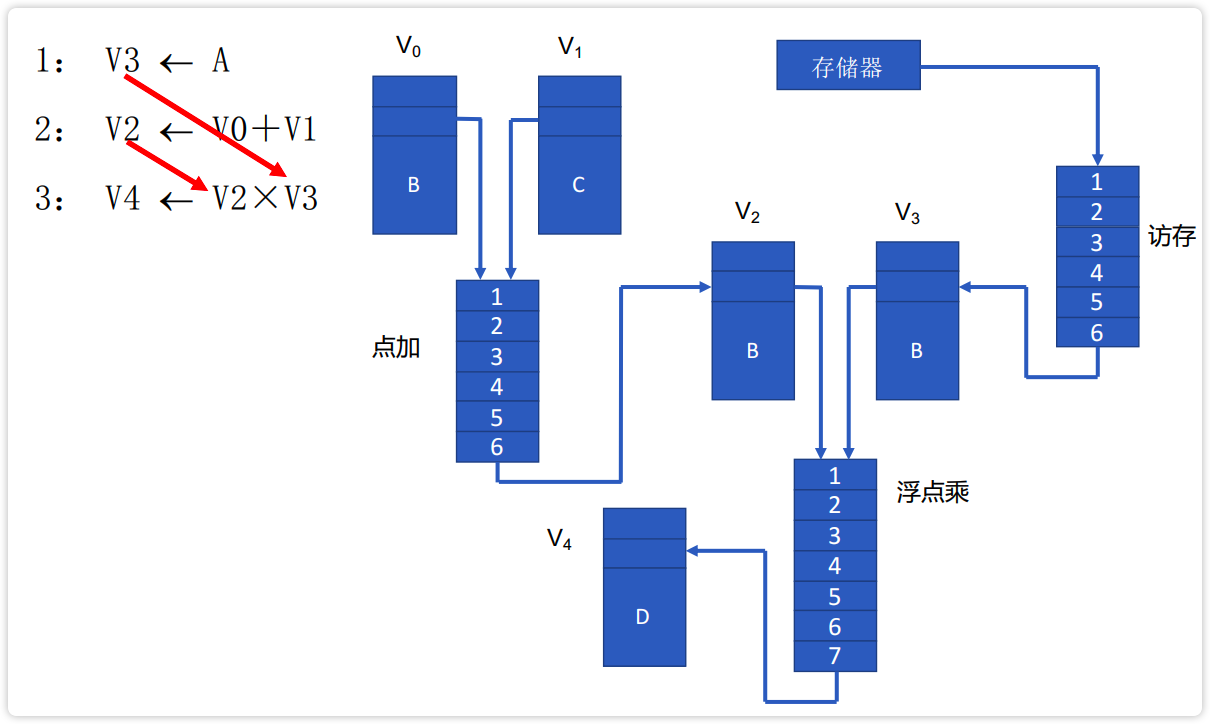


向量链接的要求 * **

阵列处理机(SIMD)
2 种构形
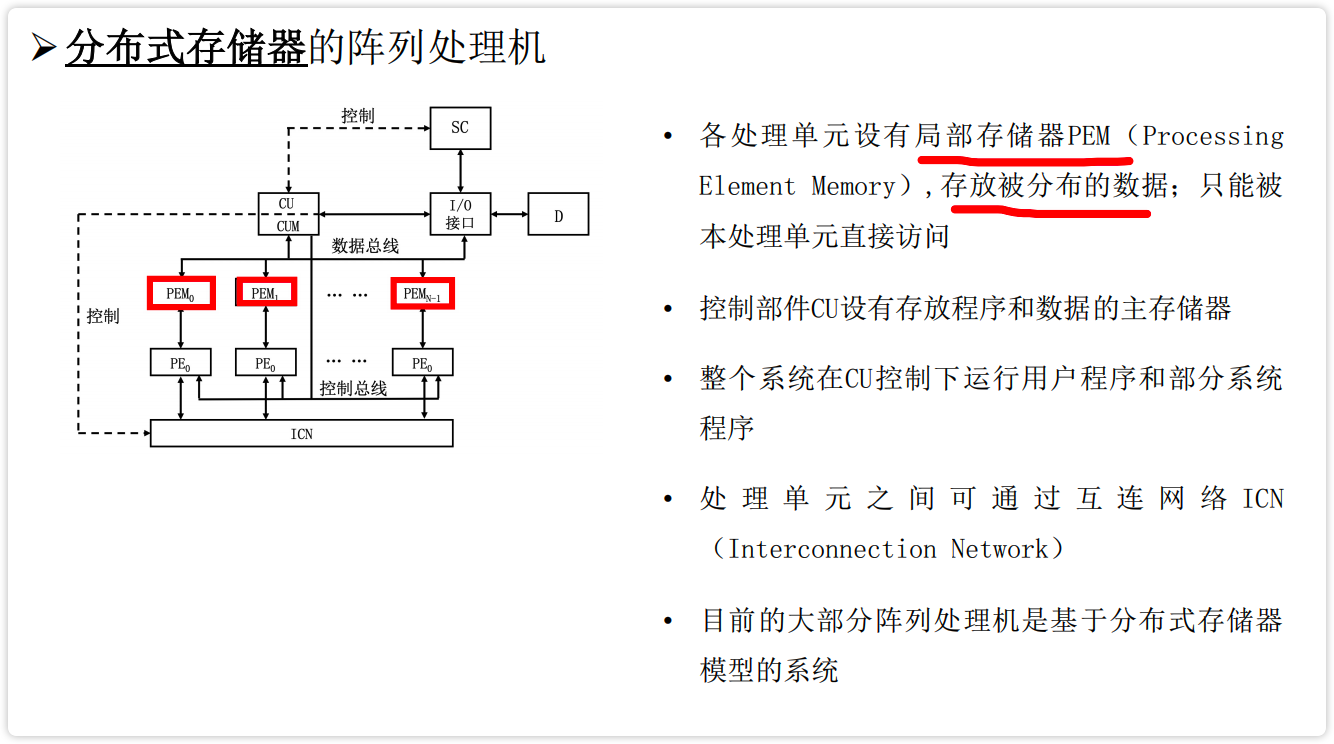
- 分布式存储器的阵列处理机构形
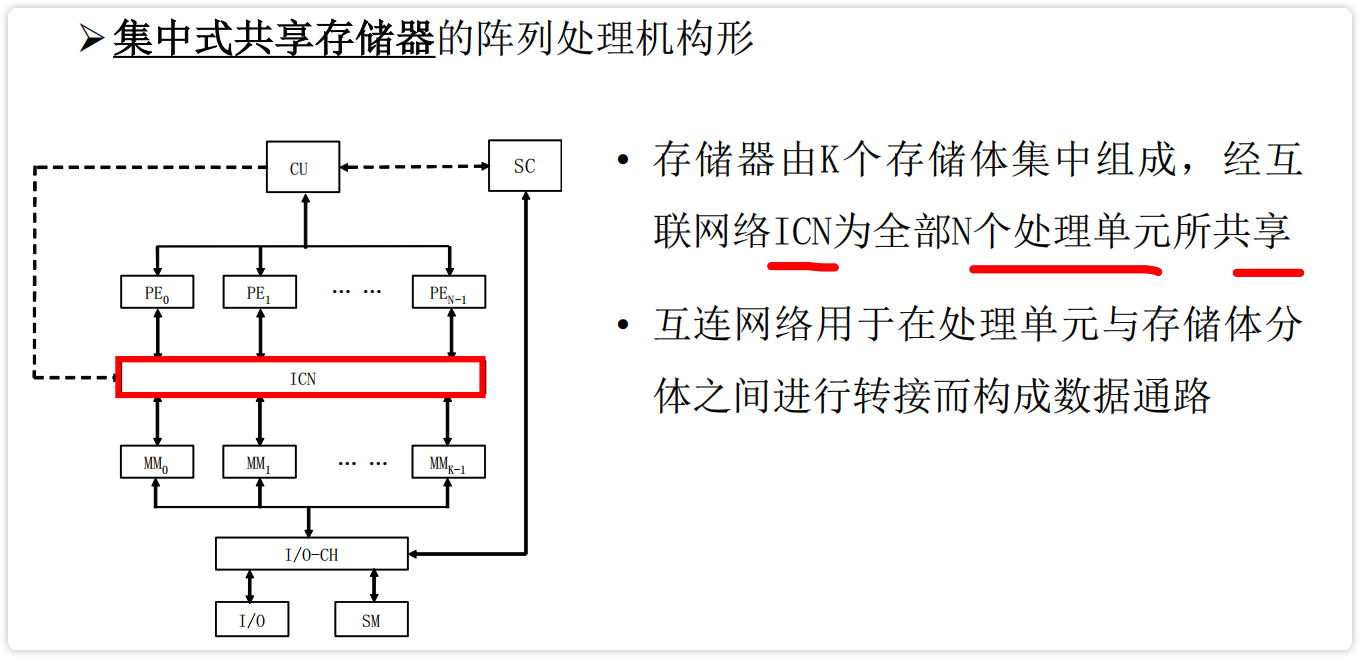
- 集中式共享存储器的阵列处理机构形
【图】分布式存储器的阵列处理机构形
image-20230225130823211
【图】集中式共享存储器的阵列处理机构形
image-20230225131007514
阵列处理机的特点 ^ *
详细特点参见《计算机系统结构(2012版)》/李学干/p210
- 基于科学计算的诉求发展起来的,与并行算法紧密联系。
- 利用资源重复和并行性中的同时性来提高自身的效率。
- 处理单元之间是基于简单规整的互连网络构建起来的(设计重点)
与流水处理机的区别 ^ *
- 阵列处理机利用的是资源重复和并行性中的同时性,流水处理机利用的是时间重叠和并行性中的并发性;
- 阵列处理机使用简单规整的互连网络来确定PE间的连接,流水处理机的功能部件比较固定。
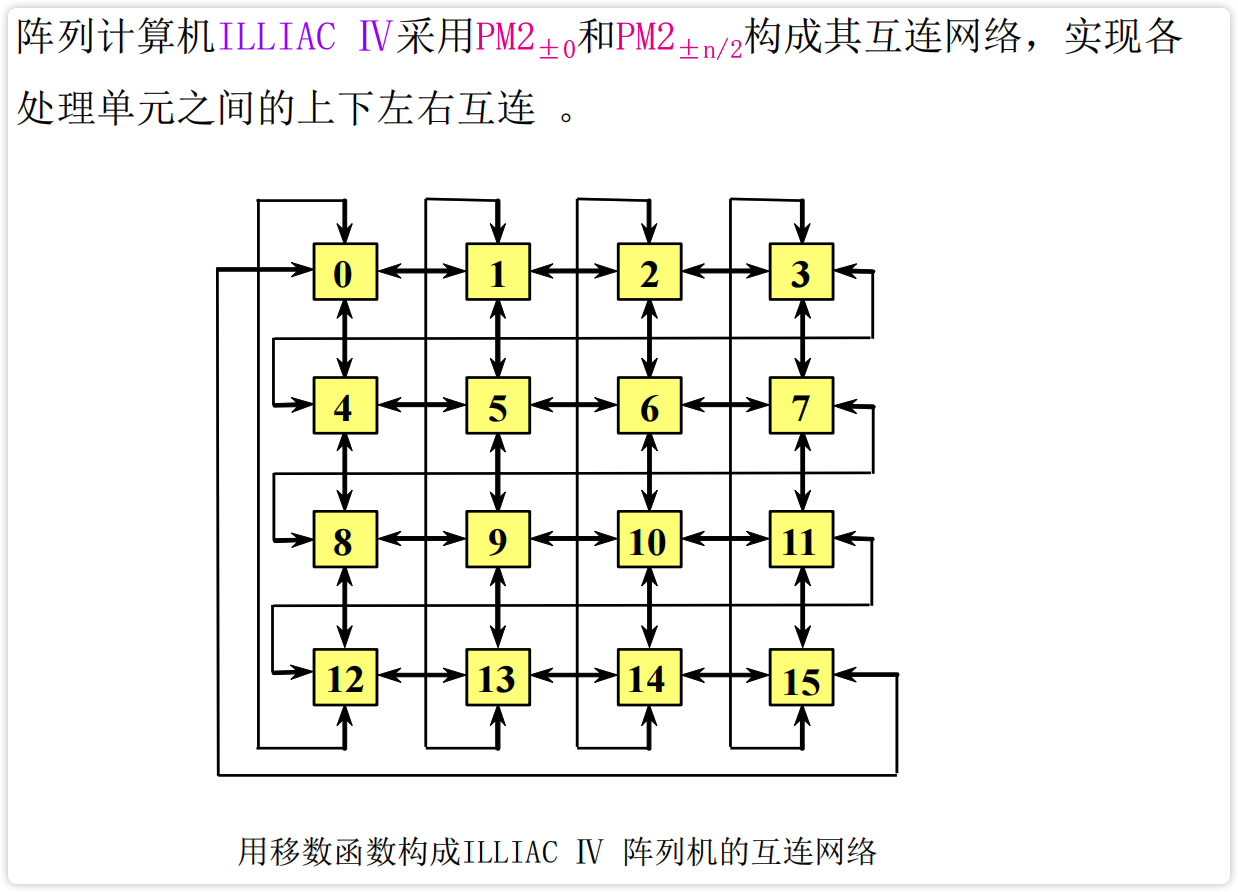
ILLIAC IV 的处理单元阵列构形 **
【图】ILLIAC IV 阵列机 (属于分布式存储器构形)
image-20230225132142072
ILLIAC IV 矩阵加 **
ILLIAC IV 矩阵乘 **
ILLIAC IV 累加和 **
SIMD 互连网络 *
互连网络是一种由开关元件按照一定的拓扑结构和控制方式构成的网络,用来实现计算机系统中节点之间的相互连接。其中,节点可以是处理器、存储模块或其他设备。
- 互连网络已成为并行处理系统的核心组成部分
- 互连网络对整个计算机系统的性能价格比有着决定性的影响
SIMD 互连网络需要弄清以下4点:
- 概念
- 设计目标 *
- 抉择问题
- 互连网络
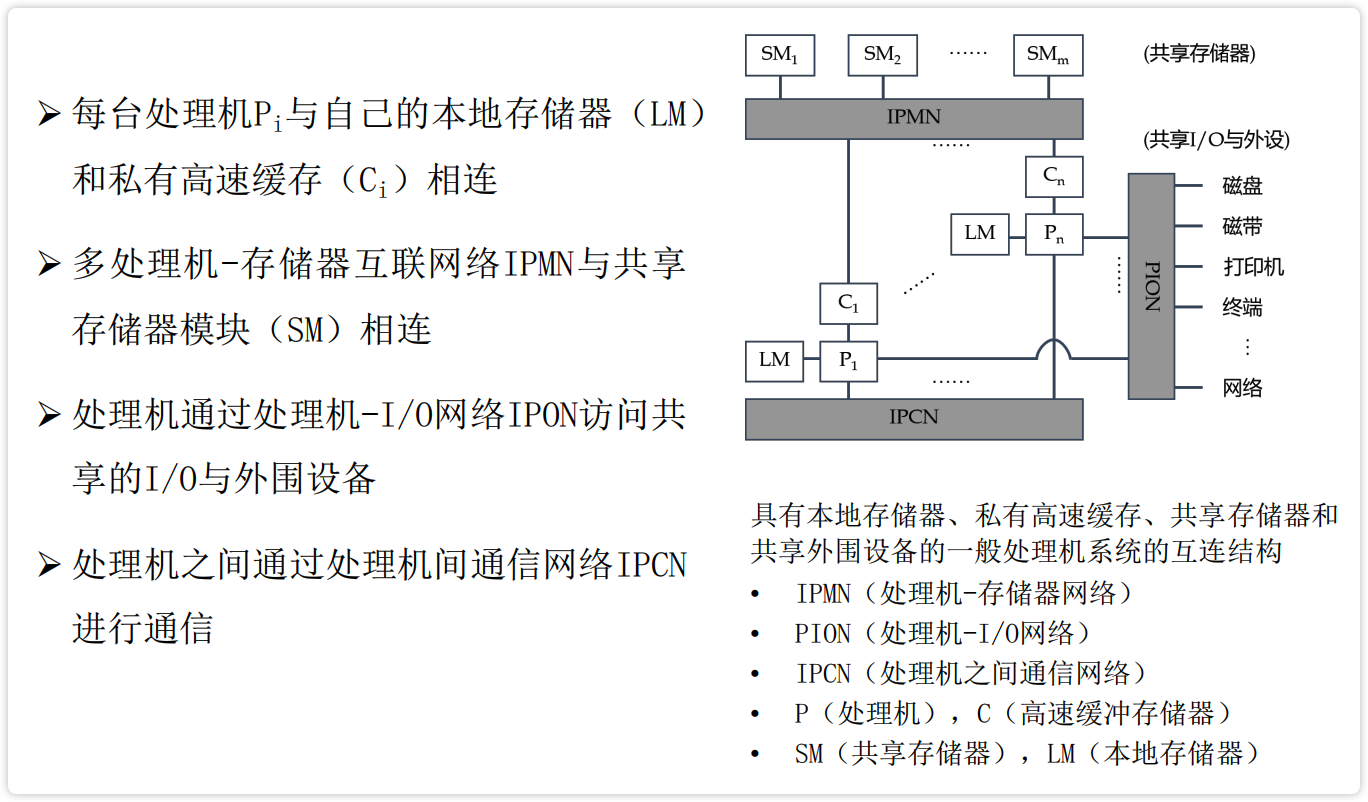
【图】具有本地存储器、私有高速缓存、共享存储器和共享外围设备的一般处理机系统的互连结构
image-20230226122555095
设计目标 * ^
SIMD 系统的互连网络的设计目标:结构不要太复杂,以降低成本;互连要灵活,以满足算法和应用的需要;处理单元间信息交换步数要少,以提高性能;能用规整单一的基本构件组合而成,或经多次通过或经多级连接实现复杂的互连,使模块性好,便于用 $VLSI$ 实现并满足系统的可扩充性。
简记 ^
- 结构不要太复杂,以降低成本。
- 互连要灵活,以满足算法和应用的需要。
- PE间信息交换步数要少,以提高性能。
- 模块要规整,便于使用
VLSI提高系统的可扩充性。
抉择问题 -
在确定处理单元(PE)之间的互连网络时,需对操作方式、交换方法、控制策略、拓扑结构做出抉择
对于操作方式,有同步、异步、同步与异步组合3种方式。
对于交换方法,有线路交换、包交换和线路与包交换组合3种方式。
对于控制策略,有集中控制、分布控制2种方式。
对于拓扑结构,有静态、动态2种方式,静态方面有一维的线性、二维的环型、星型、树型、胖树型、网络型、脉动阵列型、三维的弦环形、立方体型,由于静态网络的灵活性、适应性都比较差,很少使用,因此知道即可,动态方面有单级和多级2种。其中,动态单级网络只有有限的几种连接,必须经循环多次通过,才能实现任意两个处理单元之间的信息传输。动态多级网络是由多个单机网络串联组成,以实现任意两个处理单元间的连接。
互连种类 * **
基本的单级互连网络
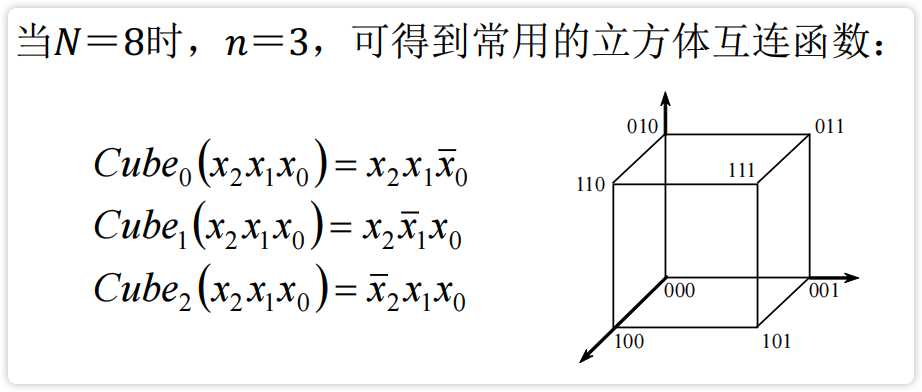
1、立方体单机网络(Cube)
实现二进制地址编码中第 $k$ 位互反的输入端与输出端之间的连接。
$$
C_k\left(x_{n-1} x_{n-2} \cdots x_1 x_0\right)=x_{n-1} x_{n-2} \cdots \overline{x_k} \cdots x_0
$$
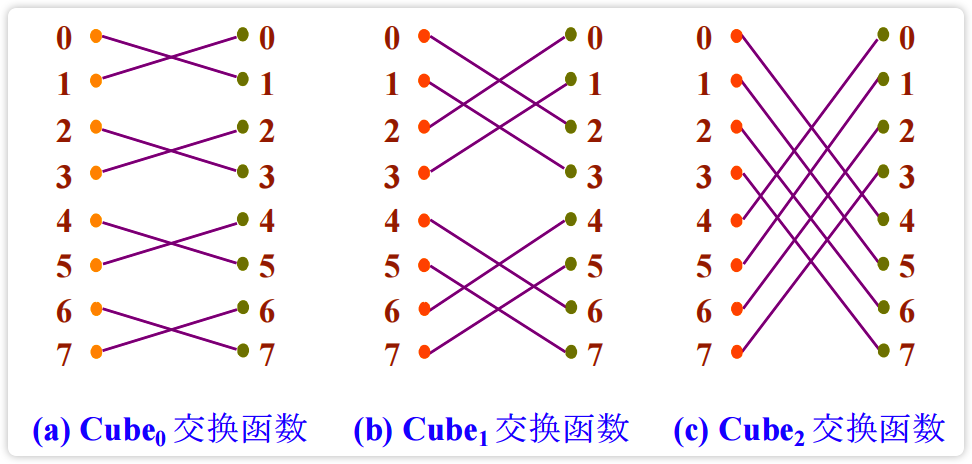
【图】Cube 交换函数
image-20230226141954914 以 $Cube_0$ 为例,第0位互反的输入端与输出端进行连接:
000 001 010 100 101 110 001 000 011 101 100 111 0连1 1连0 2连3 4连5 5连4 6连7 image-20230226142611971 从上面坐标你能够直观看出各PE之间的互连情况,如 $110$ 与 $001$ 是基于 $Cube_2$ 实现互联的, $110$ 与 $100$ 是基于 $Cube_1$ 互连的。
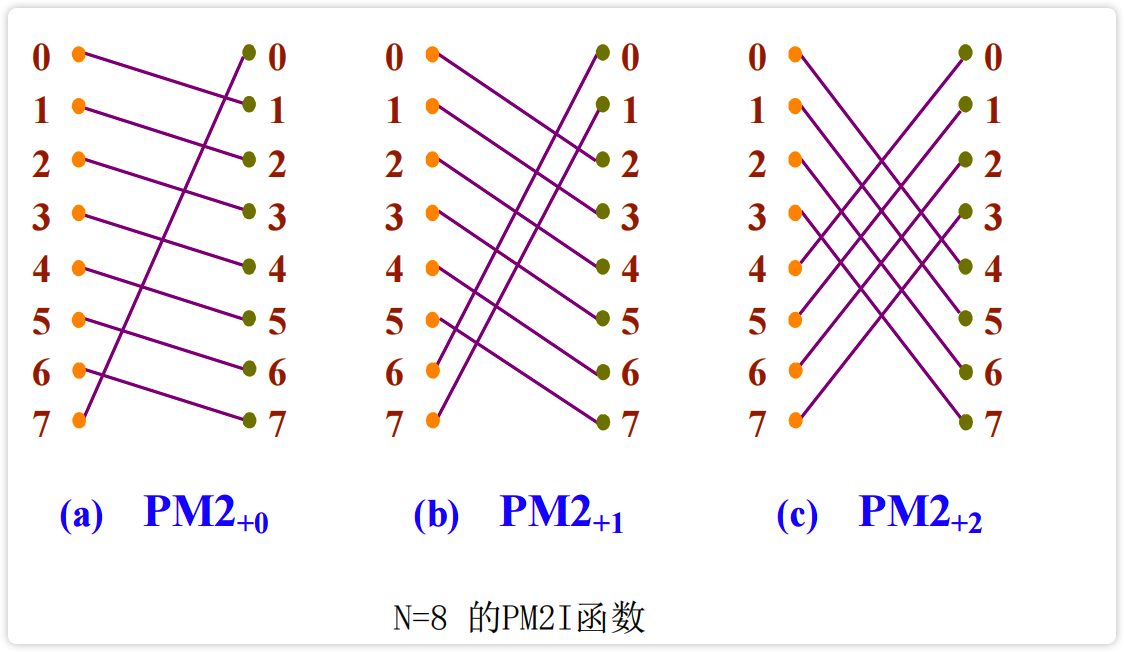
2、PM2I 单级网络 (PM21)
$P$ 表示加,$M$ 表示减,2I表示 $2^i$ 。PM2I是一种移数网络,将各输入端都错开一定位置(模N)后连到输出端,其互连函数为:
$$
\begin{aligned}
& P M 2_{+i}(x)=x+2^i \bmod N \
& P M 2_{-i}(x)=x-2^i \bmod N
\end{aligned}
$$
其中: $0 \leq x \leq N-1,0 \leq i \leq n-1, n=\log _2 N, N$ 为节点数,PM2I有 $2n-1$ 互连函数,其PM2I单机网络的最大距离为「N/2」。
【图】 N = 8 时,有 6 个 PM2I 函数
image-20230226143518915 image-20230226143528655

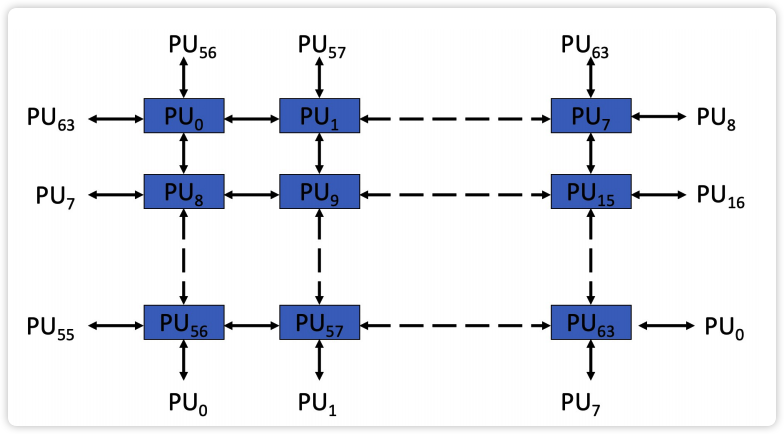
【图】 ILLIAC IV 的互连网络
image-20230226143846729
3、混洗交换单级网络(Shuffle)
简言之:把最高位挪到最低位。
$$
\sigma\left(x_{n-1} x_{n-2} \cdots x_1 x_0\right)=x_{n-2} x_{n-3} \cdots x_1 x_0 x_{n-1}
$$
在混洗交换网络中,最远的两个入、出端是全0和全1,它们的连接需要 n 次交换和 n-1 次混洗(简记:n交n-1洗),因此其最大距离为 2n-1。
4、蝶形单级网络(Butterfly)
简言之:最高位和最低位互换位置。
$$
\beta\left( \mathbf{x_{n-1}} x_{n-2} \cdots x_1 x_0\right)=x_0 x_{n-2} \cdots x_1 \mathbf{x_{n-1}}
$$
基本的多级互连网络
SIMD 和 MIMD 都是采用 多级互连网络(Multistage Interconnection Network,简称MIN)。不同的多级互连网络,在所用的交换开关、拓扑结构、控制方式各有不同。
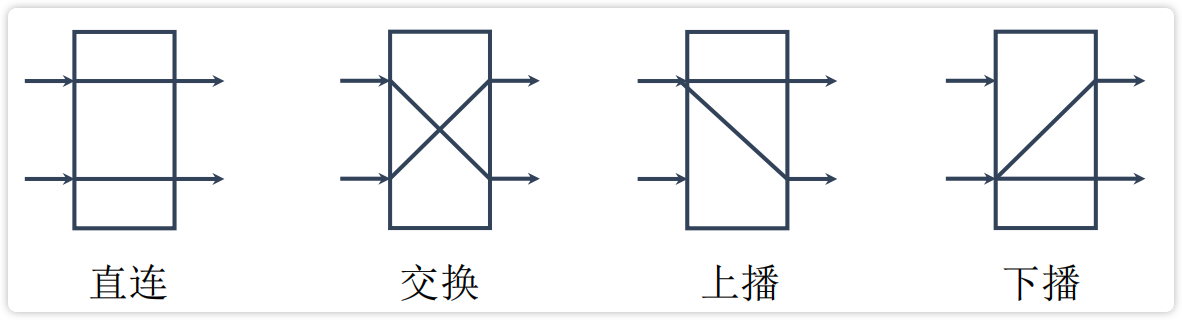
对于交换开关,有4种:直连、交换、上播、下播
【图】4种交换开关
image-20230226145411377
对于控制方式,有级控制、单元控制、部分级控制。
对于拓扑结构,有多级立方体、多级混洗、多级PM2I等。
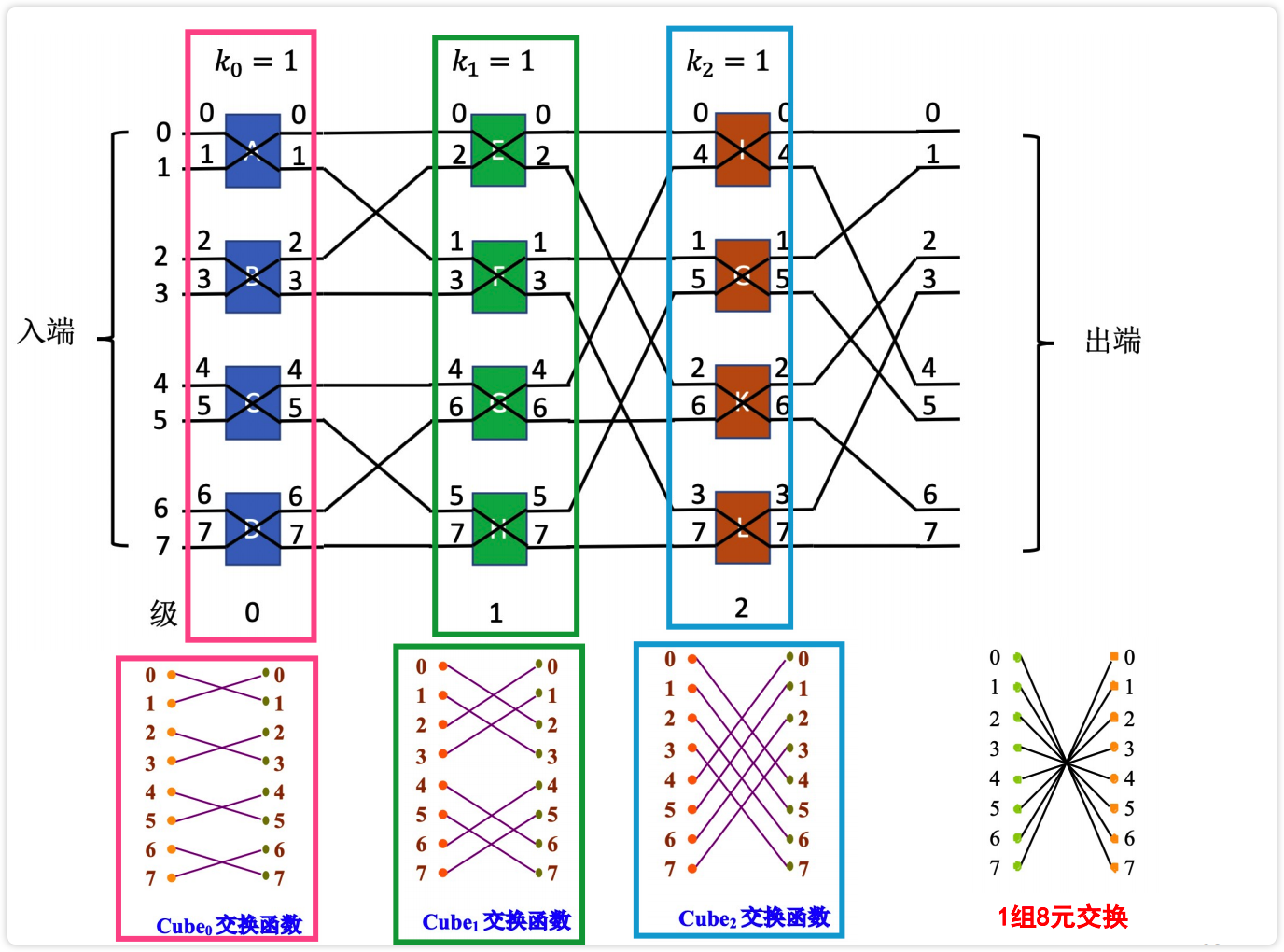
1、多级立方体
多级立方体网络包含 STARAN 网络 和 间接二进制n方体网络。 ^
- 二者共同点:都采用二功能交换开关。
- 二者差异点:在控制方式上,
STARAN采用的是级控制和部分级控制,间接二进制n方体采用的是单元级控制。
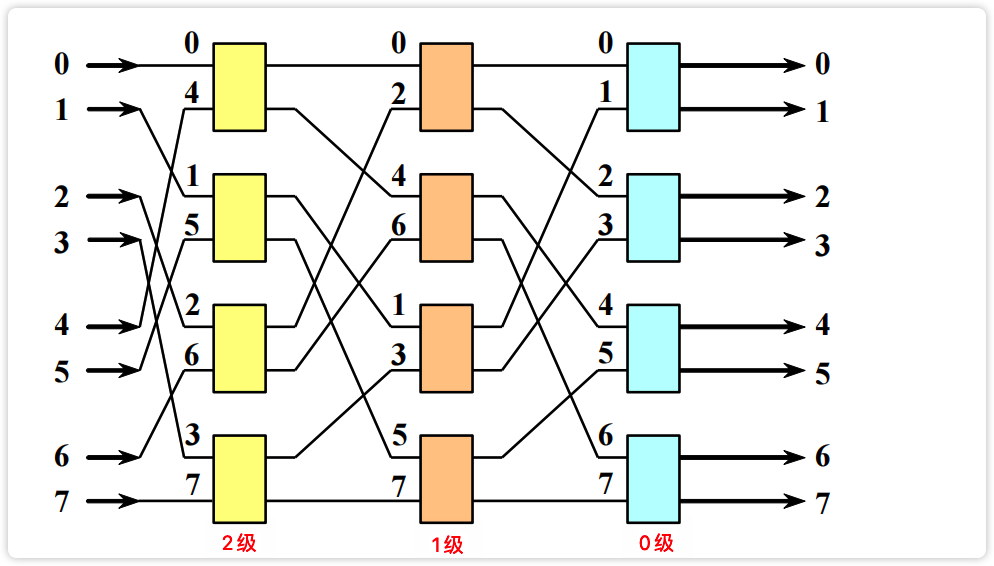
多级立方体网络对各个交换开关的控制方式:^
- 级控制。同级的所有开关只用一个控制信号控制,且只能处于同种状态。
- 单元控制。每个开关都有各自独立的控制信号,可各自处于不同状态。
- 部分级控制。第$i$级的所有开关分布用$i+1$个信号控制。
【图】多级立方体网络
image-20230226150438987
2、多级混洗交换网络(Omega)
【图】一个 8×8 的 Omega 网络
- 每级由4个四功能的2×2开关构成
- 级间互联采用均匀洗牌方式连接 (最高位挪到最低位)
image-20230226152049003
3、多级PM2I网络 **
4、其他网络
其他网络,包括基准网络、多级交叉开关网络、多级蝶式网络详见教材:
《计算机系统结构(2012版)》/李学干/p224-226
全排列网络
有 $N!$ 种映象的互连网络,叫全排列网络;实现全排列网络的两种方法:
- ① 在多级互连网络的输出端设置锁存器,使数据在时间上顺序通行两次;
- ② 将一个多级互连网络和它的逆网络串接起来,合并掉中间完全重复的一级。
共享主存构形的阵列处理机中并行存储器的无冲突访问 **
【图】第1种情形
image-20230226155017117 【图】第2种情形
image-20230226155038807 【图】第3种情形
image-20230226155139935



脉动阵列流水处理机
【背景】为要求计算量很大的信号/图像处理及科学计算的特定算法需求,卡内基-梅隆大学的美籍华人 H.T.Kung 于 1978 年提出**脉动阵列(Systolic Array)**处理机。其中该项设计被应用到 Google TPU 设计中。
脉动阵列结构的原理
脉动阵列结构是由一组处理单元(PE)构成的阵列。每个PE的内部结构相同,一般由一个加法/逻辑运算部件或加法/乘法运算部件再加上若干锁存器构成;阵列内所有PE的数据锁存器受一个时钟控制;运算时,输入数据流和结果数据流在阵列结构的各个PE间沿各自的方向同步向前推进。 就像血液受心脏有节奏地搏动在各条血管中同步向前流动一样,因此被称为”脉动阵列结构“
脉动阵列结构的特点 ^
脉动阵列结构有如下特点: ^
- 结构简单规整、模块化强、可扩充性好,适用于
VLSI实现。 - PE间数据通信距离短,数据流和控制流的设计以及同步控制等均简单规整。
- 所有PE都能同时运算,具有较高的计算并行性,可通过流水获得很高的运算效率和吞吐率。
- 输入数据能被多个处理单元重复使用,大大减轻了阵列与外界的IO通信量,降低对系统主存和IO频宽的要求。
- 与特定计算任务和算法密切相关,具有某种专用性,这对
VLSI不利 。
VLSI:超大规模集成电路(Very Large Scale Integration Circuit,VLSI)