标量处理机
标量处理机
真题
简答题
【重叠方式篇】
简述指令重叠的概念及实现重叠解释必须满足的要求 1510 1404
【流水方式篇】
简述多功能流水线的概念和静动态流水线分类的依据 2204
简述 IBM360/91 解决流水控制的途径 1910 ** (熟读)
源自教材习题5-10:试总结 IBM360/91 解决流水控制的一般方法、途径和特点
IMG_9805

简述超流水处理机提高指令级并行的方法和特点 1204
简述超标量处理机和超流水处理机的区别 2008 (熟读教材原话)
简述流水线机器全局性相关的概念及处理全局性相关的四种方法 2104
简述全局相关处理中,采用猜错法猜错后保证恢复分支点原先的现场的方法 2110

应用题
指令重叠执行表达式 ** **


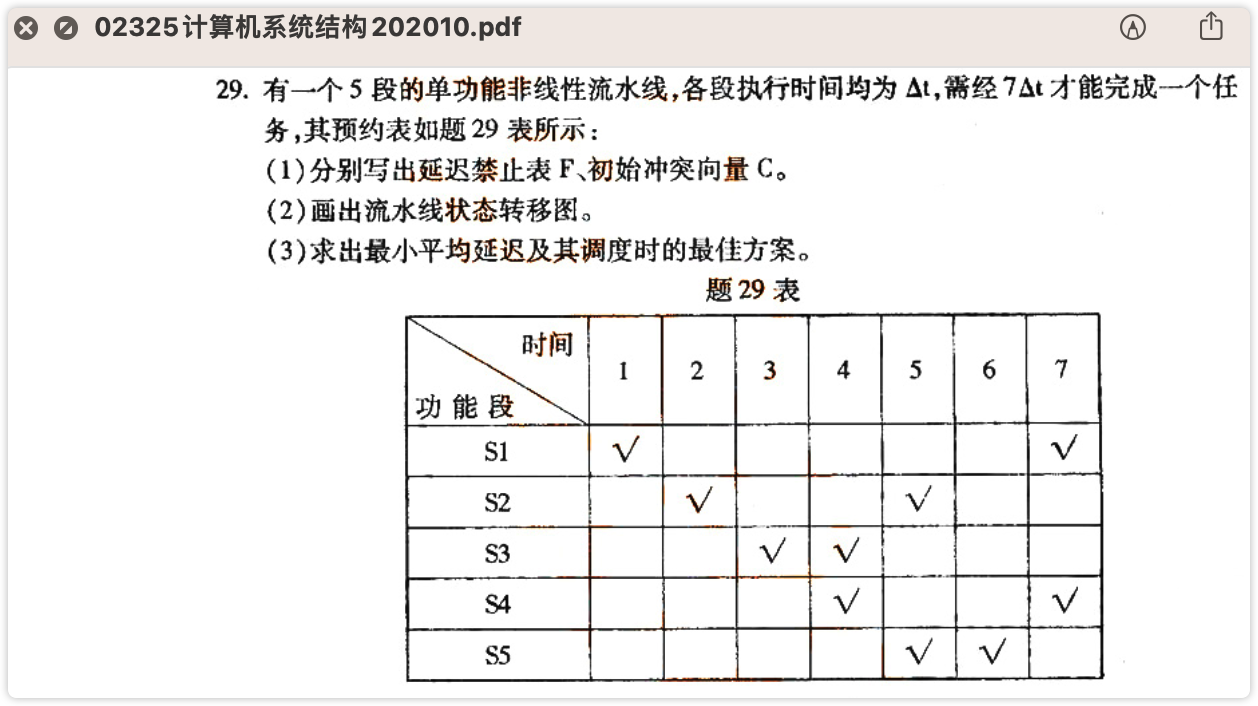
非线性流水调度
流水时空图
- 记住公式即可得分

标量处理机
只有标量数据表示和标量指令系统的处理机。
重叠方式
【图】对一条机器指令的解释一般包括3个部分:取指、分析、执行
image-20230219113240787
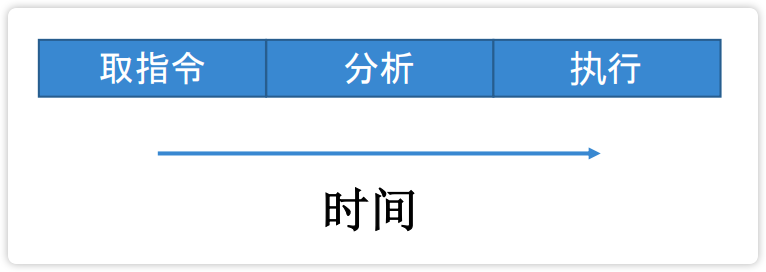
指令的重叠解释
指令重叠解释:在解释第$k$条指令操作完成之前,就可以开始解释第$k+1$条指令。 ^
实现指令重叠需要在计算机组成上满足以下几点要求:^
- 解决访主存冲突问题。
- 解决“分析”与“执行”操作的并行问题。
- 解决“分析”与“执行”操作的同步问题。(用“一次重叠”解决) *
- 解决指令相关问题。
如何解决访主存冲突问题?
结论先行,共有 3 种,但第3种最合适:
- 方式一:低位交叉存取
- 方式二:设立两个存储器,一个是指令存储器,一个是数据存储器
- 方式三:设立指令缓存寄存器(指缓),实现先行控制技术。
先行控制技术:其关键技术是缓存技术和预处理技术。
缓存技术一般用在工作速度不固定的两个功能部件之间。设置缓冲栈的目的:平滑功能部件之间的工作速度。
这种思想在编程领域被广泛应用。
如何解决分析和执行的并行问题?
在硬件上,需要有指令分析部件和指令执行部件的支持。
【例】以加法器为例:分析部件需要有地址加法器用于地址计算;执行部件需要有加法器用于完成操作数的相加运算。
如何解决分析和执行的同步问题?
在硬件上解决,保证 $执行_k$ 和 $分析_{k+1}$ 同步。
详见:《计算机系统结构(2012版)》/李学干/p170
如何解决指令相关问题?
指令的三种执行方式
1、顺序执行方式
【图】指令的顺序执行方式
image-20230219113544503 执行 $n$ 条指令,需用:


2、一次重叠执行方式
一次重叠解释:指令分析部件和指令执行部件在任何时候都只有相邻两条指令在重叠解释。因此任何时候都只需要保证 $执行_k$ 与 $分析_{k+1}$ 重叠。此种执行方式的好处是节省硬件,简化控制。 ^
【图】指令的一次重叠执行方式 待校准
image-20230219114655826 执行 $n$ 条指令,需用:
$T=(1+2n)·t$

3、两次重叠执行方式
【图】指令的两次重叠执行方式
image-20230219114848505 执行 $n$ 条指令,需用:
$T=(2+n)·t$

重叠的相关处理
相关有两种,数相关和指令相关。其中,数相关不仅会发生在主存空间,还会发生在通用寄存器空间。因此,无论发送何种相关,或者使解释出错,或者使重叠效率显著下降,都必须加以正确处理 。 其中,在执行指令过程中,如果用到前面指令的执行结果(如指令、操作数、变址量等),则称为数据相关。^
数相关:第$k$条指令与第$k+1$条指令的数据地址之间有关联。
指令相关
发生指令相关的情景:
n : STORE R1,n+1 n+1: ···上述场景中,满足关系:结果地址 n = 指令地址 n+1。当第 n 条指令还没有把执行结果写入主存前,取出的第 n+1 条指令显然是错误的。
解决指令相关的根本办法:在程序执行过程中不允许修改指令。
IBM 370 系列机中,是通过“执行指令”来解决指令相关问题:这种方式使得程序在执行过中中,既可以修改指令,又具备可再入性。
image-20230219154046329

主存空间数相关
主存空间数相关是相邻两条指令之间出现对主存同一单元要求先写后读的关联。
发送主存操作数相关的情景:
待完善。
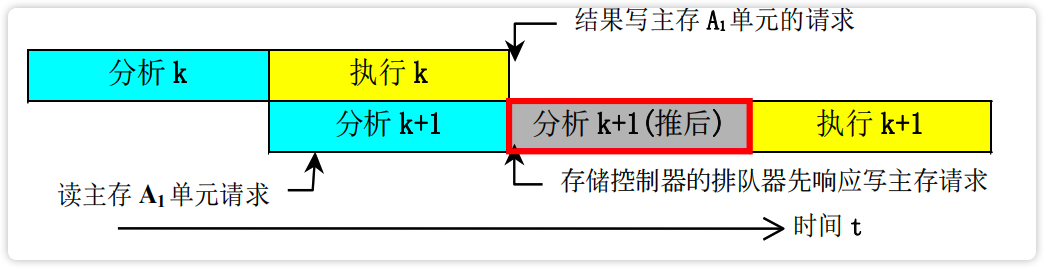
解决主存操作数相关的办法:推后 $分析_{k+1}$ 的读
【图】推后 $分析_{k+1}$ 的读
image-20230219154841787
通用寄存器组相关
通用寄存器除了存放源操作数、运算结果外,还可以存放变址值(或基址值)。因此,通用寄存器组相关有两种相关:
- 操作数相关
- 变址值或基址值相关
发生通用寄存器数据相关的情景:
解决通用寄存器数据相关的方法:
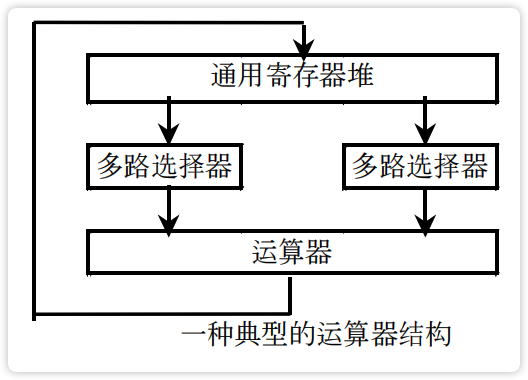
- 法1:D型触发器构成的通用寄存器,该构形允许在同一节拍中实现寄存器间的循环传送。
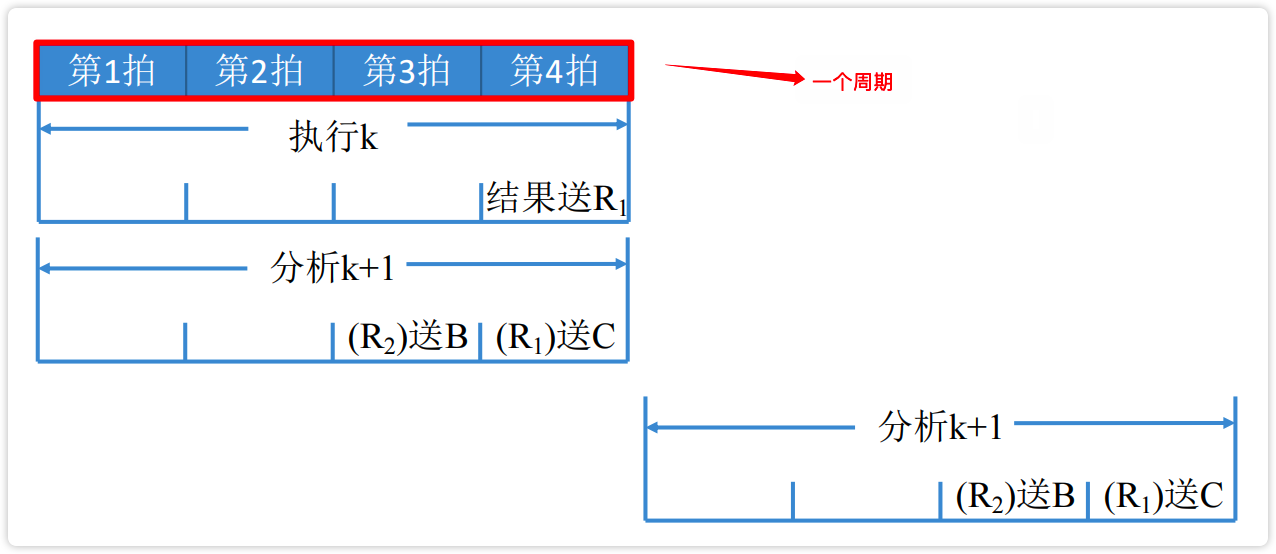
- 法2:分析指令推后一个周期执行
- 法3:分析指令推后一个节拍执行
- 法4:设置专用通路
【图】D 型触发构成的通用寄存器
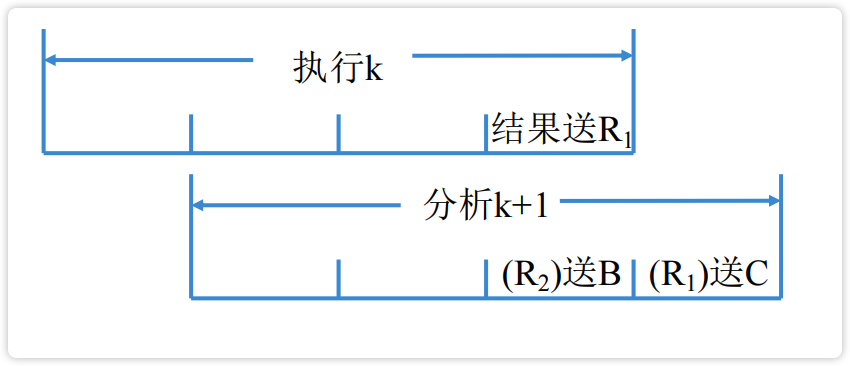
image-20230220213550084 【图】分析指令推后一个周期执行
image-20230220213811252 【图】分析指令推后一个节拍
image-20230220213848470 【图】设置专用通路
image-20230220213943438
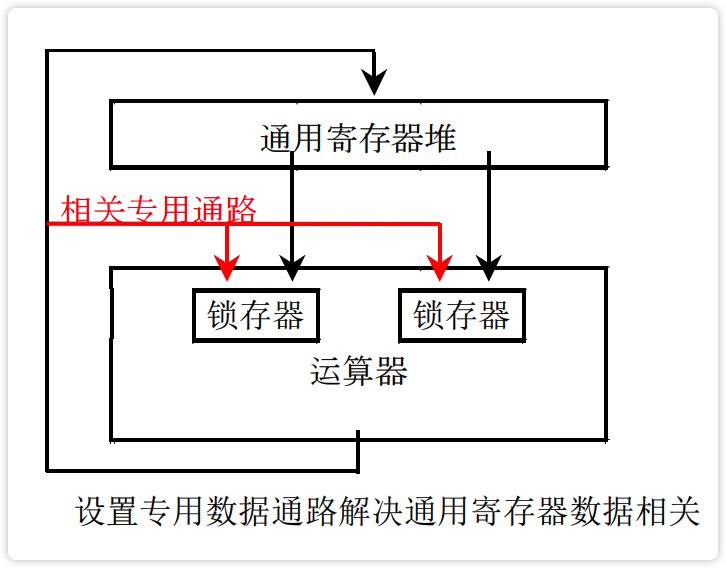
综上所述,推后 $分析_{k+1}$ 和设置相关专用通路是解决重叠方式相关处理的两种基本方法。 前者以降低速度为代价,使设备不增添;后者以增加设备为代价,使重叠效率不下降。 ^
变址相关
发生变址相关的情景:
解决变址相关的办法:
- 法1:推后分析。
- 法2:设置变址相关专用通路
【图】设置变址相关专用通路
image-20230220214919164
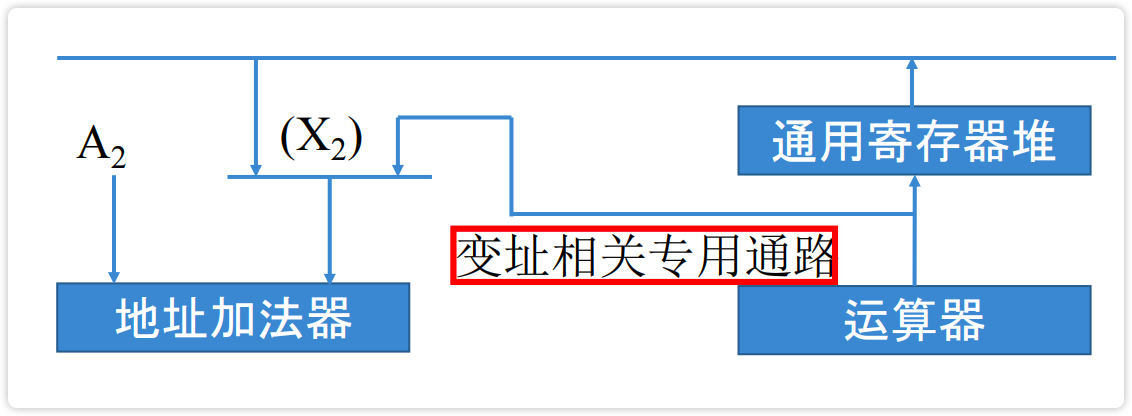
流水方式
流水方式是把一个重复的过程分解为若干个子过程,每个子过程可以与其他子过程同时进行。处理机的各个部分都可以采用流水方式工作。如:
- 指令执行过程可以采用流水方式。
- 运算器操作部件可以采用流水方式。
- 访问主存储部件可以采用流水方式。
- 处理机之间可以采用流水方式。
流水特点:
- 只有连续提供同类任务才能发挥流水效率
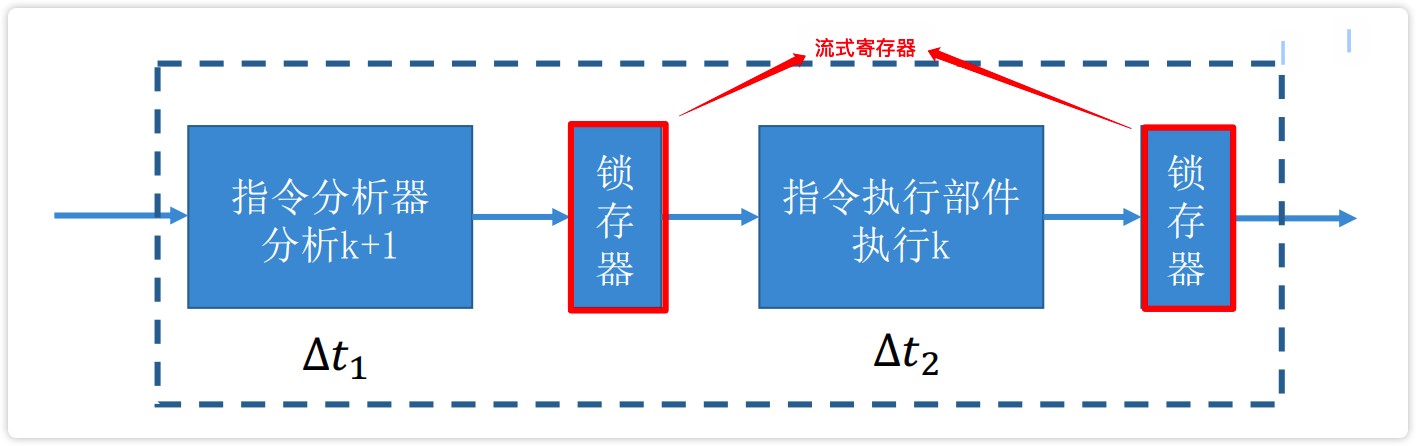
- 每个流水段都要设置一个流水寄存器
- 各流水段的时间应尽量相等
- 流水线需有“装入时间”和“排空时间”
【图】流水寄存器
image-20230222185751419
【图】浮点加法器流水时空图
image-20230222185913122 image-20230222185859626

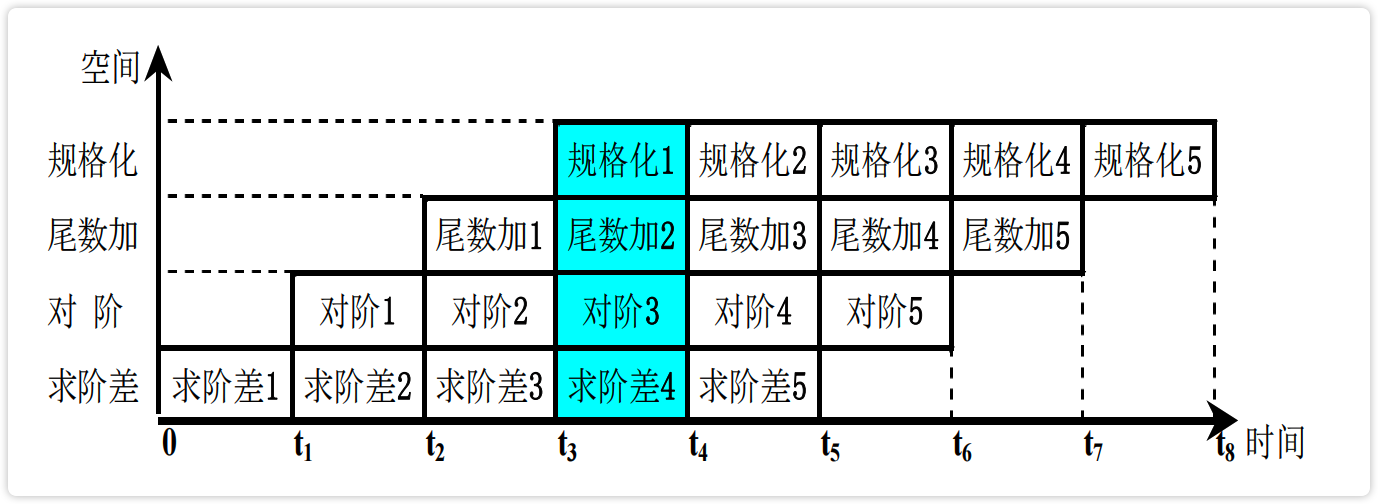
流水分类 * ^
- 按是否有反馈分:线性、非线性
- 按级别分:部件级、处理机级、系统级
- 按功能分:单功能、多功能
- 按数据表示分:标量流水、向量流水
- 按控制方式分:同步流水、异步流水
按是否有反馈信号分:
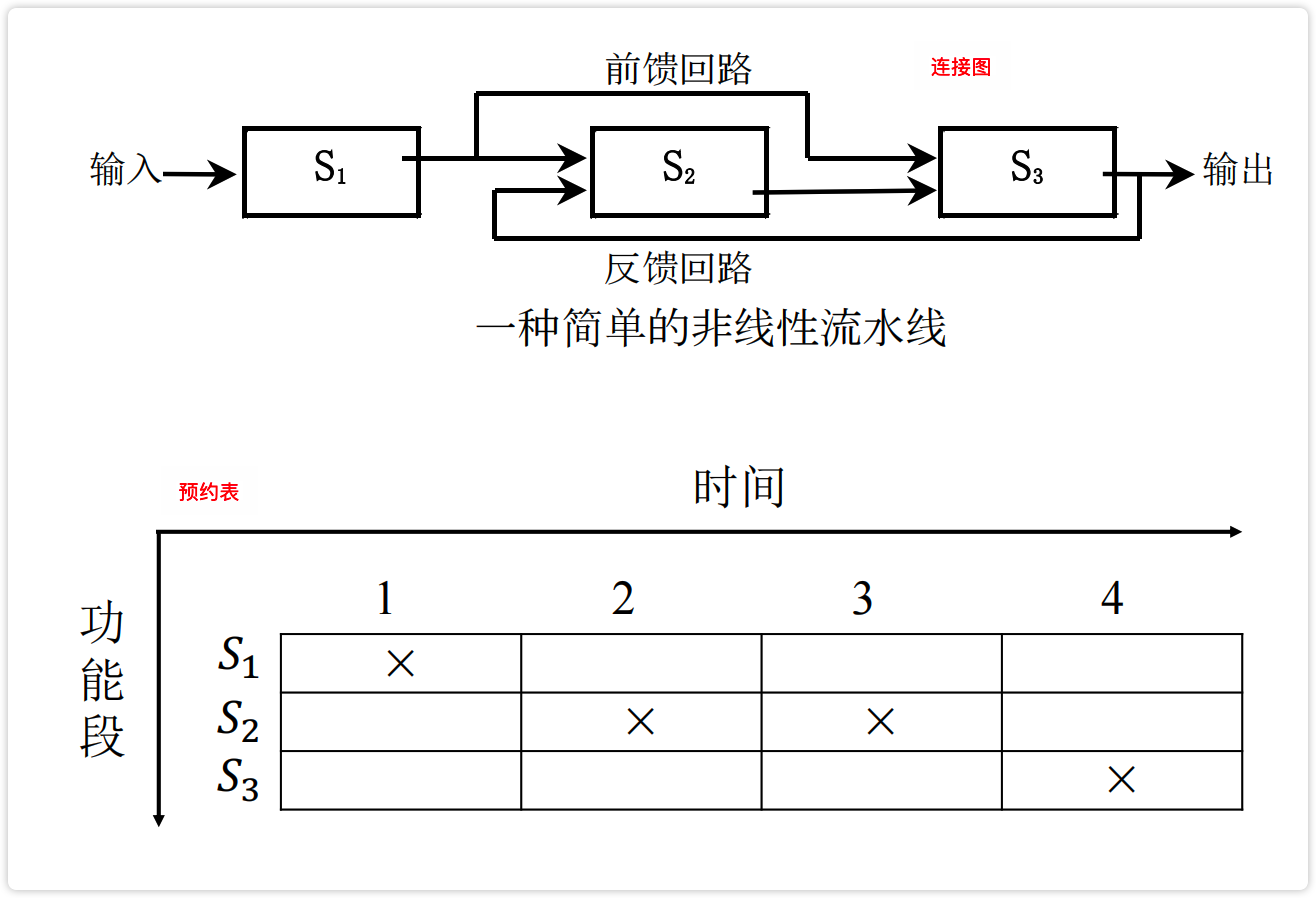
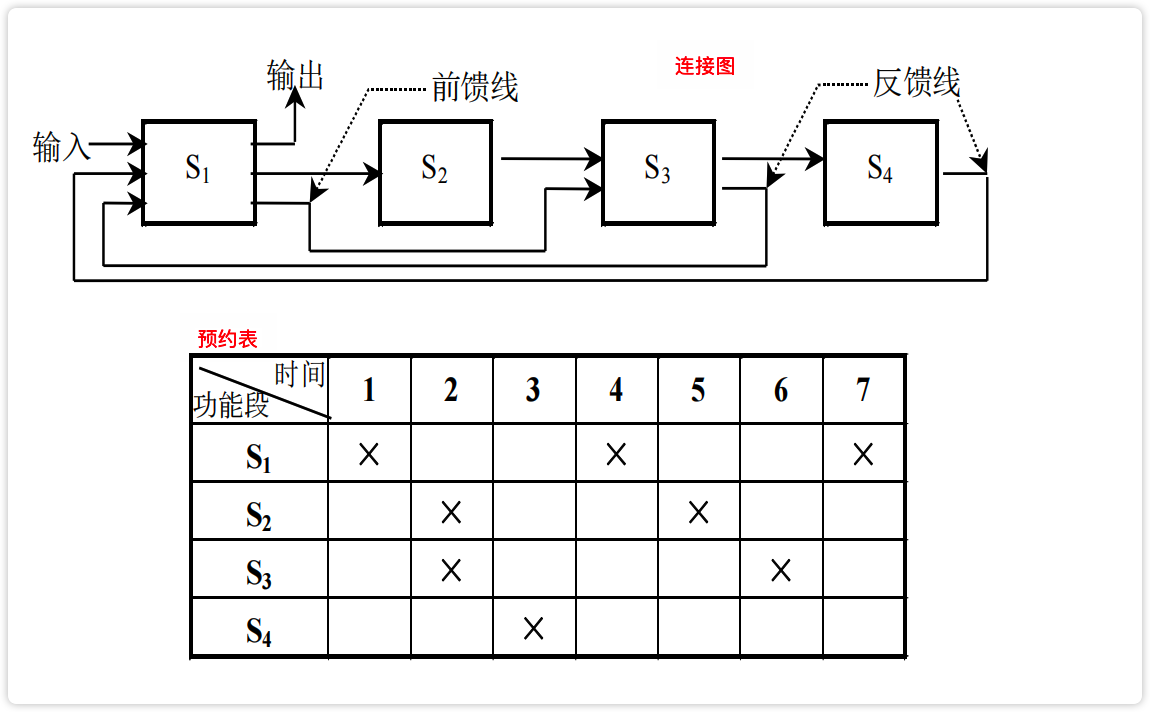
线性流水:每个流水段都流过一次且仅流过一次。
非线性流水:某些流水段之间有反馈回路或前馈回路。
二者的区别在于线性流水仅用连接图表示即可,非线性流水需要连接图+预约表共同表示才行。
【图】非线性流水的连接图和预约表
image-20230222190537190
按级别分
部件级流水:部件内各个子部件间的流水。
【图】浮点加法器的流水线
image-20230222192038245
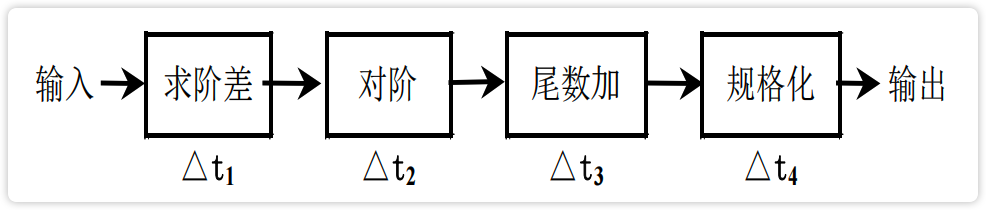
处理机级流水:处理机的各部件的流水。
【图】处理机之间的流水线
image-20230222192109967

系统级流水:多个处理机之间的流水。
按单多功能分
单功能流水:只能实现单一功能的流水。
多功能流水:同一流水线的各段之间可以有多种不同的连接方式以满足不同的运算需求。 p178 图5-17
按静动态分
静态多功能流水:一次只实现一种运算功能。
动态多功能流水:在同一段时间内,各段可以按照不同的方式链接,同时执行多种功能。
【图】静态流水线
image-20230222192415207
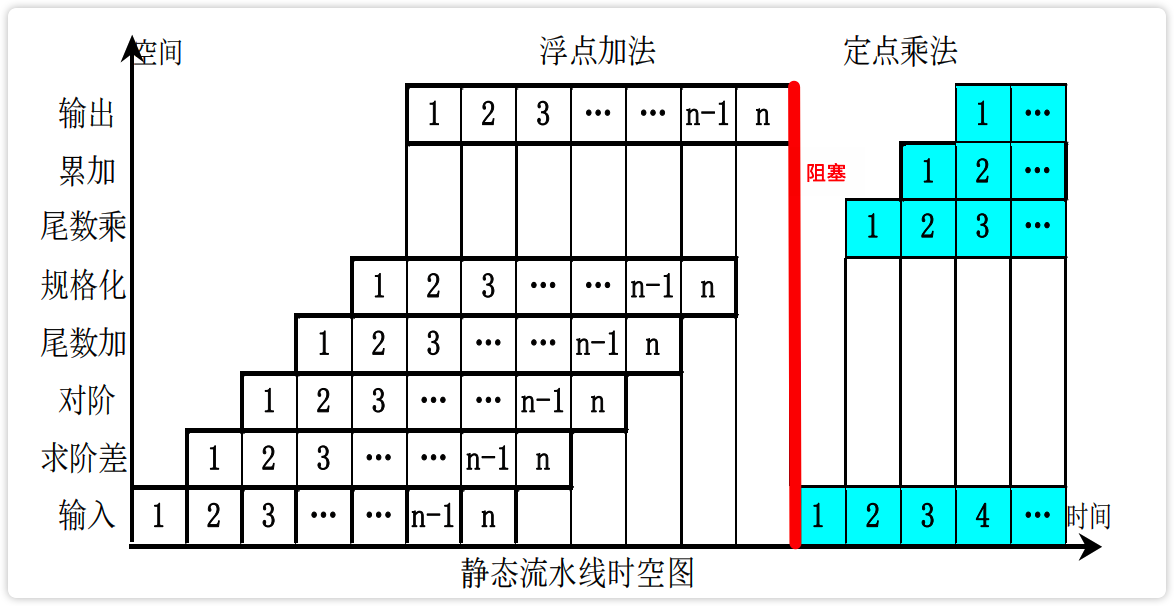
【图】动态流水线
image-20230222192652845
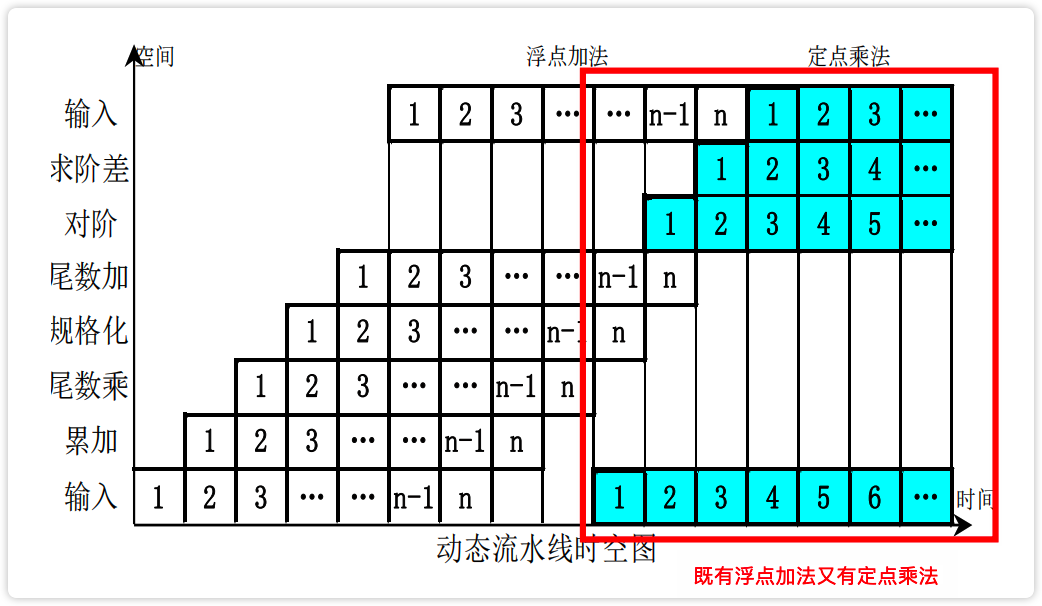
其他分类
按数据表示分:标量流水和向量流水
按控制方式分:同步流水和异步流水
流水的性能分析
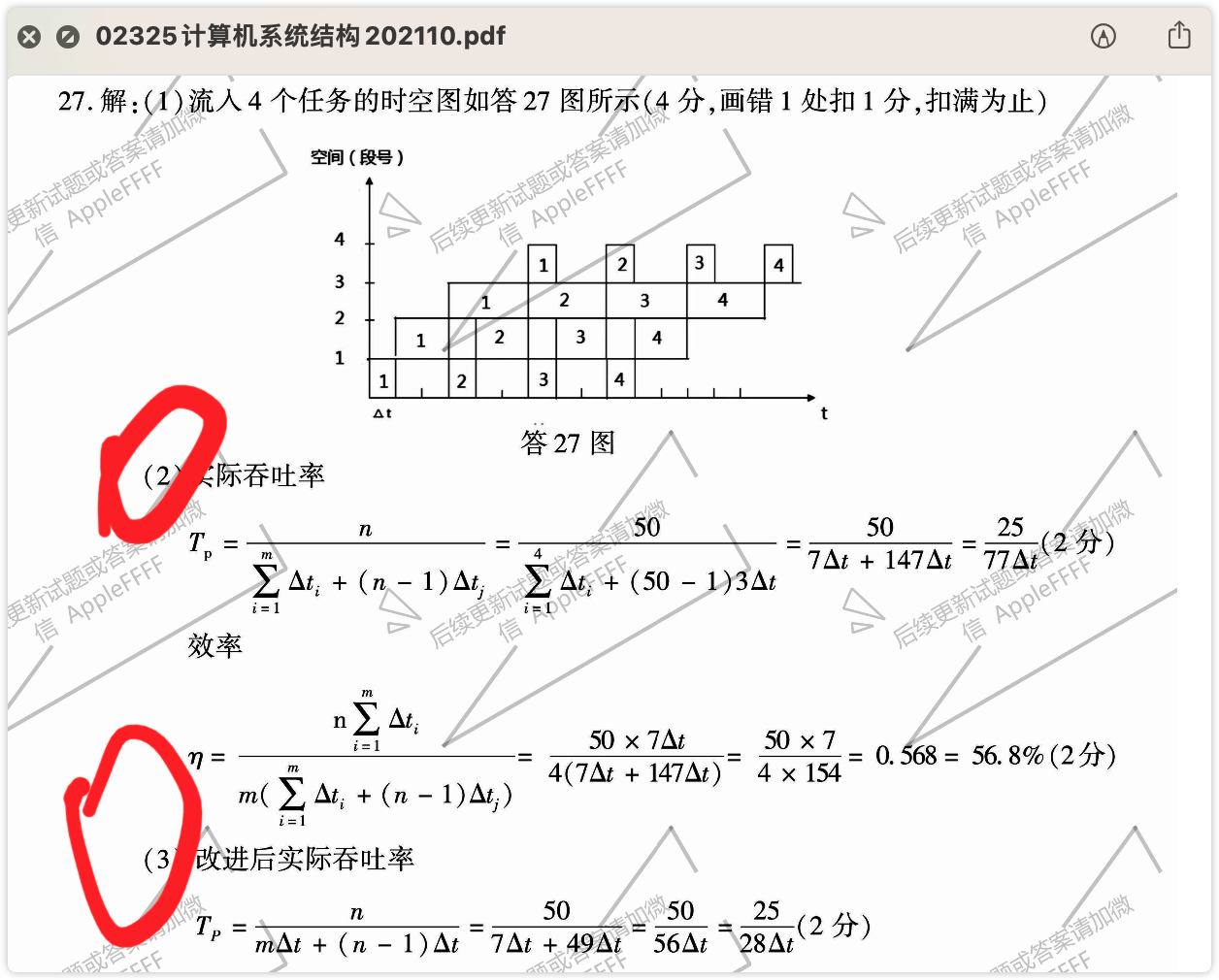
流水的性能指标主要有仨:吞吐率、加速比、效率。
- 吞吐率:流水线单位时间里能流出的任务数或结果数、
- 加速比:用于表示流水方式相对于非流水方式速度提高的比值
- 效率:流水线中设备的实际使用时间占整个运行时间之比
计算流水性能指标时,一定要结合时空图进行巧算速算。
简记:吞吐率看线段,效率看面积
吞吐率
基本公式
$$
T_p=\frac{n}{T_k}
$$
其中,$T_k$ 是完成 n 个任务所用的时间,且需分两种情况讨论:
- 各段时间相等时:
$$
T_k=(k+n-1)·Δt
$$
其中,$k$ 为流水线的段数,$Δt$ 为时钟周期
- 各段时间不等时:
$$
T_p=\frac{n}{\sum_{i=1}^k \Delta t_i+(n-1) \max \left(\Delta \mathrm{t}1, \cdots, \Delta \mathrm{t}{\mathrm{k}}\right)}
$$
时空图速算技巧:
$$
吞吐率=\frac{任务数n}{完成n个任务数所用的时间}
$$
提高流水的吞吐率,主要是消除瓶颈子过程。其中瓶颈子过程是指流水线中经过时间最长的子过程。消除瓶颈子过程的主要方法有:
- 将瓶颈子过程再分解。
- 设置多套瓶颈段并联。
效率
基本公式
$$
E=\frac{n \cdot \sum_{i=1}^k \Delta t_i}{k·T_k}
$$
其中,$k$ 为流水段数,$T_k$ 是完成 n 个任务所用的时间,且需分两种情况讨论:
- 各段时间相等时:
$$
T_k=(k+n-1)·Δt
$$
- 各段时间不等时:
$$
T_k=\sum_{i=1}^k \Delta t_i+(n-1) \max \left(\Delta \mathrm{t}1, \cdots, \Delta \mathrm{t}{\mathrm{k}}\right)
$$
时空图速算技巧:
$$
效率=\frac{n个任务占用的时空面积}{k个流水线的总时空面积}
$$
【例】线性流水的性能分析与计算
image-20230222193259692 image-20230222193742380
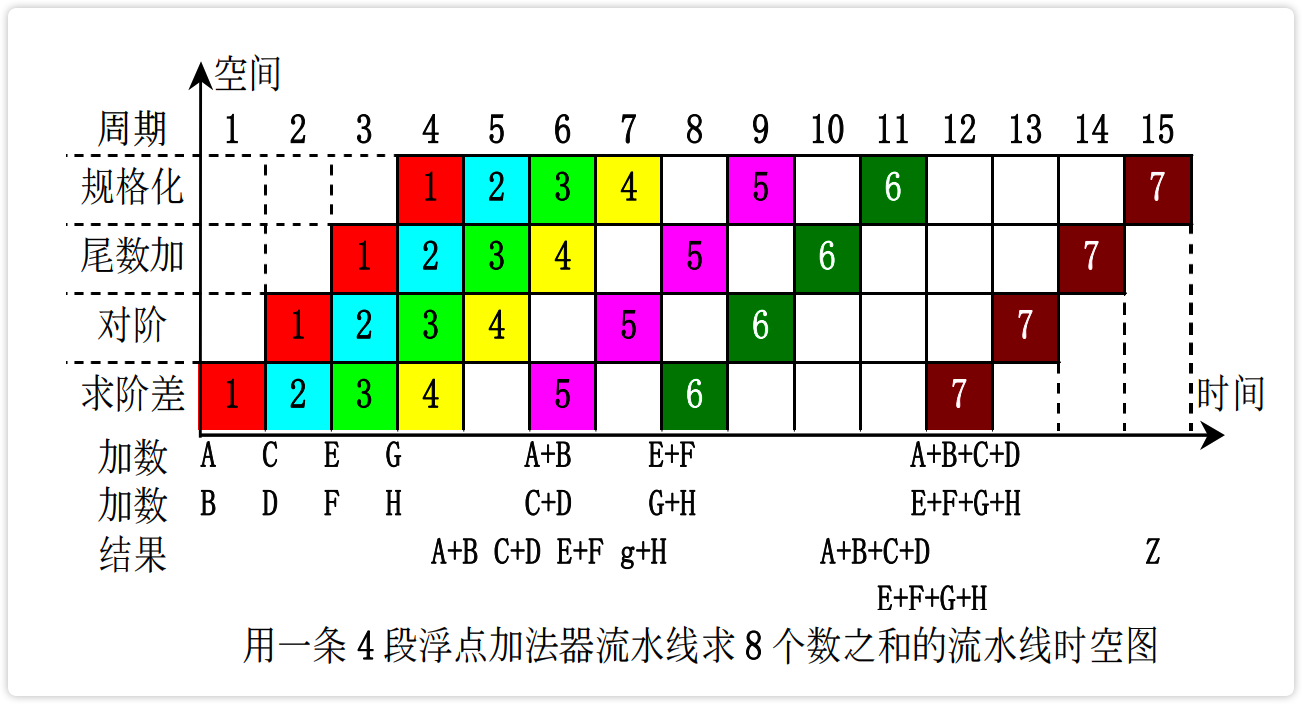

吞、加、效的关系

非线性流水的调度 *
非线性流水调度的任务是要找出一个最小的循环周期,按照此周期向流水线输入新任务,流水线的各个功能段都不会发生冲突,且吞吐率和效率最高。
非线性流水线需要连接图和预约表共同表示才能找到所谓的“最小循环周期”。
⚠️ 学习非线性流水调度,重点在学懂看**“预约表”**,只要看懂嘞预约表就能从中到得以下信息:
- 延迟禁止向量
- 初始冲突向量
- 根据初始冲突向量画状态图
- 根据状态图写出调度方案并找到最佳调度方案以及计算出流水的最大吞吐量。
【图】非线性流水线的连接图和预约表
image-20230222194159933
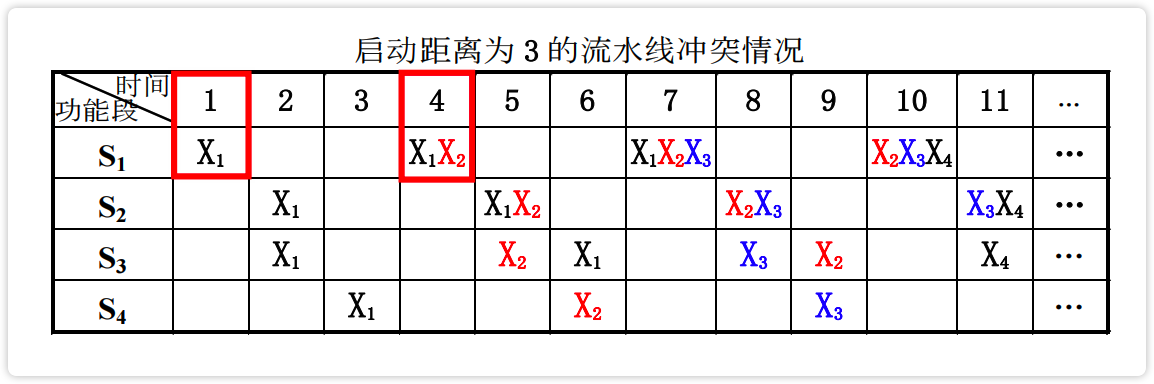
非线性流水的冲突及解决
冲突场景
了解即可,对非线性流水的冲突有一个直观的印象即可。
【图】启动距离为3的流水线冲突情况
image-20230223193502679 【图】启动距离为2的流水冲突情况
image-20230223193704881
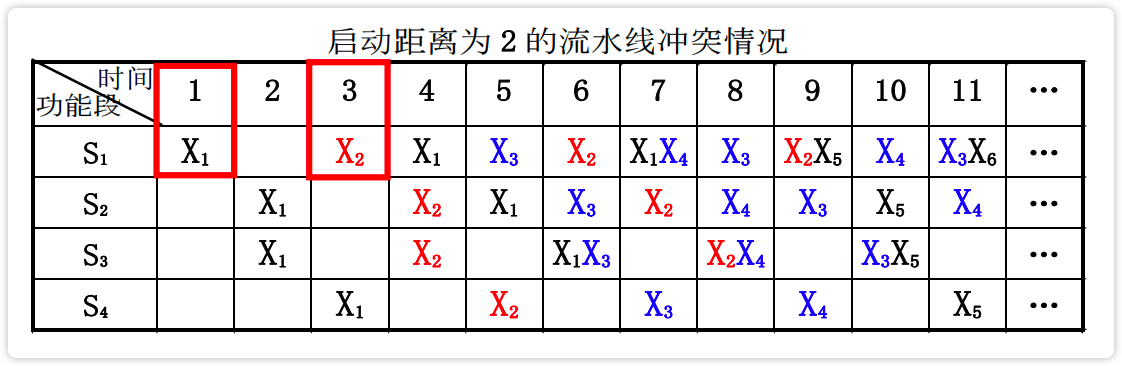
解决办法 *
引入延迟禁止向量、初始冲突向量、状态图,借助这3样东西找到“最小的循环周期”。其中延迟禁止向量、初始冲突向量概念如下:
延迟禁止向量:预约表中每一行任何两个"X"之间距离的集合。
初始冲突向量:$C=(C_mC_{m-1}···C_2C_1)$,其中m是禁止向量中的最大值。
非线性流水冲突的解决办法是在 1971 年由 E.S.Davidson 及其学生提出
如何确定延迟禁止向量?
如何确定初始冲突向量?
初始冲突向量的式子:$CN-1···Ci···C2C1$ N是拍数(上面那张图的拍数是7)
以上图为例,根据延迟禁止向量$F={1,3,6}$,在对应的位置填1,其余填0
| C6 | C5 | C4 | C3 | C2 | C1 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 1 |
由此得出初始冲突向量为:$C(100101)$
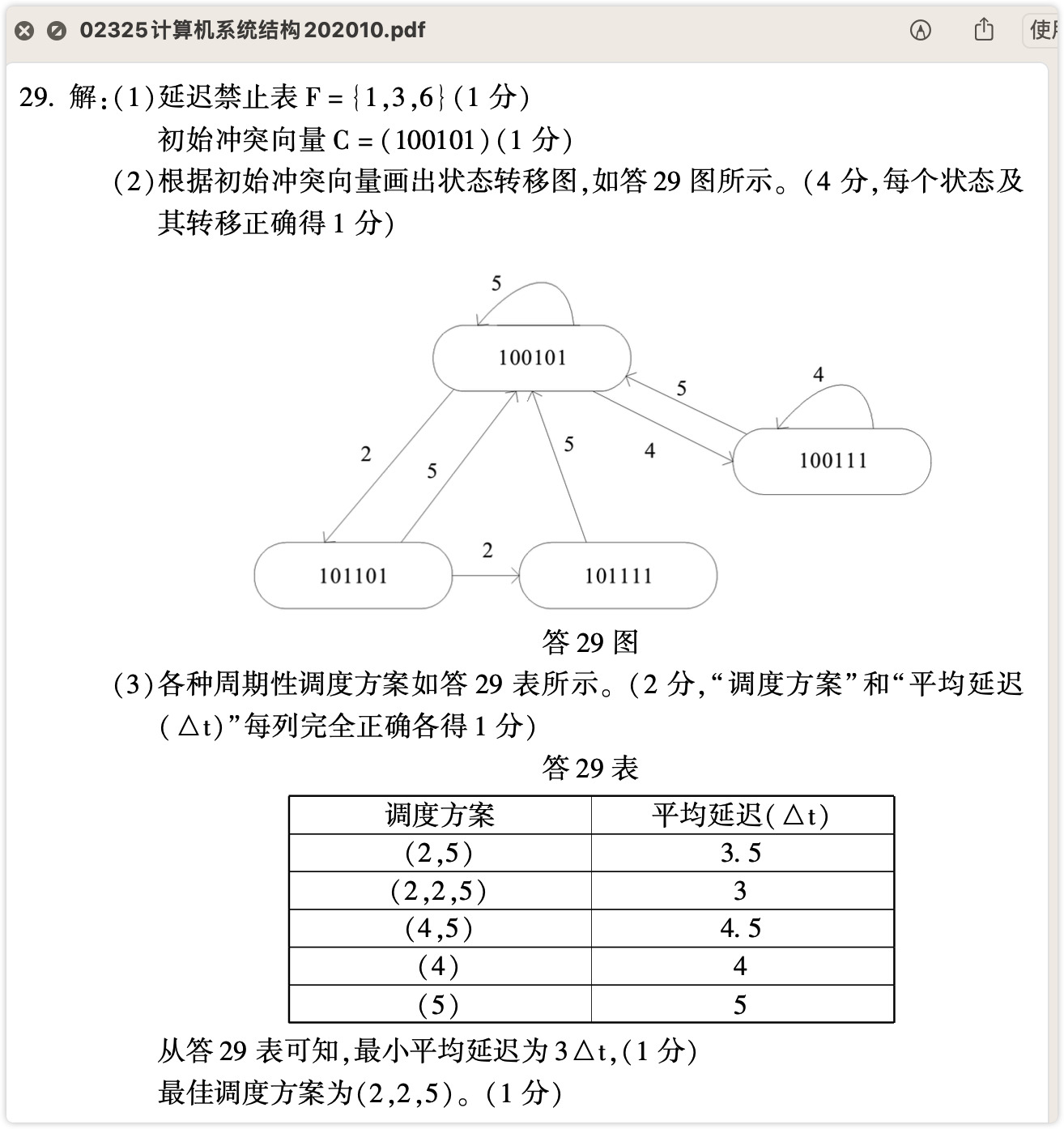
如何根据初始冲突向量画出状态转移图?
如何根据状态转移图罗列调度方案?
能形成闭环的,就算一种调度方案。如上图有:(2,5)、(2,2,5)、(4,5)、(4)、(5)。
对上述解答有质疑,因为1904#28题的最佳调度方案不符我的预期,需要进一步理解怎样才可算一种调度方案,以及如何正确罗列调度方案。
如何在调度方案中确定最佳调度方案及该方案的最小平均延迟?
根据状态转移图罗列所有的调度方案,箭头连接可构成一个闭环算一种方案
如何给出当前流水的最大吞吐量?
只要找到了最佳调度方法并算出其最小平均延迟,即可求得当前流水的最大吞吐率:$Tp=1/最小平均延迟$
流水的相关处理
局部相关
全局相关 ^
全局性相关:转移指令和其后的指令之间存在关联,使得处理机不能同时解释,造成对流水机器的吞吐率和效率的下降。严格来说就是已进入流水线的转移指令和其后续指令之间相关。
如何处理全局性相关问题 ?(两个加快,一个猜测,一个转移)
- 加快和提前形成条件码;
- 加快短循环程序的处理。
- 使用猜测法;
- 采取延迟转移;
指令级高度并行的超级处理机 **
自 20 世纪 80 年代 RISC 兴起后,出现了提高指令级并行的高性能超级处理机,使得单处理可以在每个时钟周期里解释多条指令。如:
- 超标量处理机
- 超流水线处理机
- 超标量超流水线处理机
- 超长指令字处理机
超标量处理机
略。
超流水线处理机
【问】简述超流水处理机提高指令级并行的方法和特点 1204
【答】方法:着重开发时间并行性,在公共硬件上采用短时钟周期和深度流水来提高速度;特点:并行度高;充分利用公共硬件;但需要高速时钟机制,否则无法实现超流水线。
超标量和超流水处理机的区别 ^ *
【问】超标量处理机和超流水处理机的区别 2008
【答】超标量处理机利用资源重复,设置多个执行部件寄存器堆端口。超流水线处理机则着重开发时间并行性,在公共的硬件上采用短时钟周期和深度流水来提高速度。
超标量超流水线处理机
超标量超流水线处理机是超标量流水线和超流水线处理机的结合。
【问】什么是超标量超流水处理机?
【答】超标量超流水处理机是超标量流水线和超流水线的结合。
超长指令字处理机
超长指令字结构是将水平型微码和超标量处理相结合。 ^