2024 年日志
重要
重要文字
相关信息
信息文字
提示
提示文字
注意
注意文字
警告
警告文字
注
注释文字
2024 年日志
12月日志
相关信息
CentOS-8.5.2111-x86_64-boot.iso
提示
自建的应用服务器,需要做哪些配置初始化工作,这些工作是否可以通过脚本实现一步到位的初始化工作,比如:
- 设置服务器名
- 设置时区
- 关闭防火墙
- …
参考:
- 阮一峰:Linux服务器的初步配置流程
- Linux服务器初始化工作
- 服务器性能优化
- CPU使用情况,可以使用
htop查看 - 内存使用情况,可以使用
htop查看 - 磁盘IO使用情况,可以使用
iostat查看 - 平均负载情况,可以使用
htop查看 - 网络使用情况,可以使用
nload查看 - 检查服务器调优参数是否设置合理:单个进程最大打开文件数、TCP相关设置。
- CPU使用情况,可以使用
相关信息
杨波 分布式系统案例课
简明思路框架:
- 功能性需求(API)
- 用例 ~ 用户群体等
- 输入输出
- 非功能性需求
- 高性能 ~ 快速读写
- 高可用 ~ 不丢数据,灾难恢复
- 可扩展 ~ 根据读写规模按需扩展
- 成本(开发、运维)
- 其他 ~ 研发学习门槛
相关信息
杨波 分布式系统案例课
微服务的关注点分两大类:公共关注点、业务关注点。二者侧重不同,对于公共关注点,Service Mesh(服务网格) 正在让其变得无感且易于治理,以便让开发更加专注于业务开发。
公共关注点一般需要关注:
- 服务发现/负载均衡
- 边界代理/网关
- 配置中心
- 调度和发布
- 监控治理
- 限流容错
- 流量治理
- 安全治理
业务关注点一般关注:
- 数据一致性分发
- 数据聚合
- 分布式事务
- 单体系统解耦拆分(即如何向微服务架构演进)
- …
- 分布式锁
- 延迟队列任务
相关信息
Vuepress-hope-theme + Algolia 实现全文搜索
相关信息
透明多级分流系统
客户端缓存
域名解析
传输链路
HTTP/1.X (HTTP over TCP)
HTTP/2.X (HTTP over TCP)
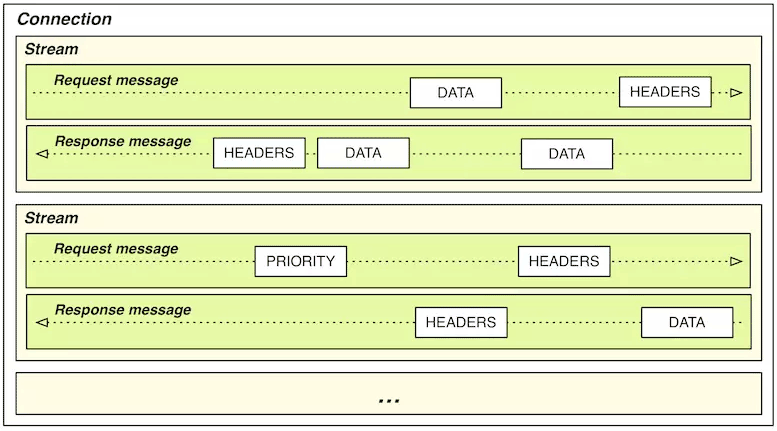
HTTP/3.X (HTTP over QUIC)
内容分发网络(CND)
负载均衡
集群部署 数据链路层负载均衡 网络层负载均衡 应用层负载均衡
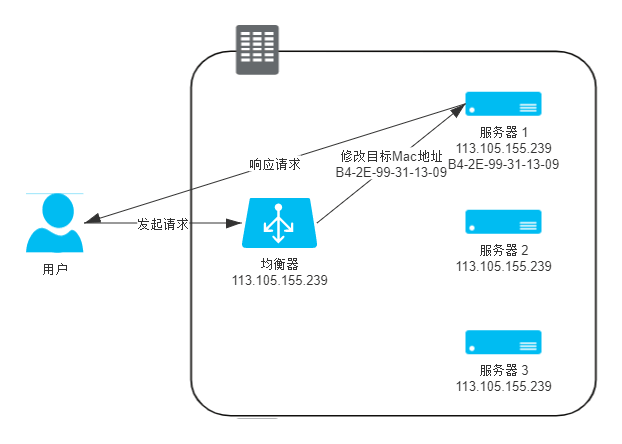
数据链路层负载均衡(效率最高)
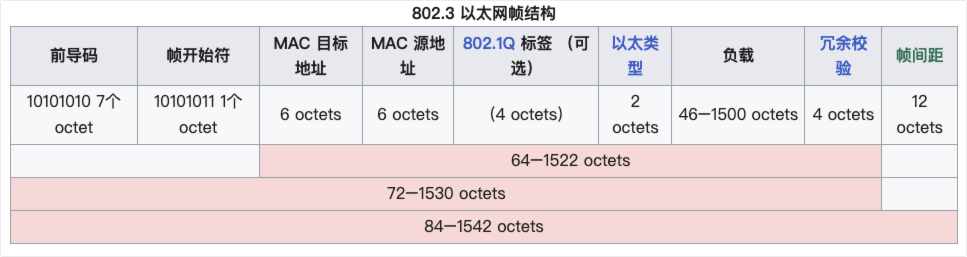
数据链路层主要负责在两个网络实体之间提供数据链路连接的简历、维持和释放管理。数据桢是该层的最小数据单元。常见的数据桢有:以太网桢、PPP桢。比如: 1500 Bytes MTU 以太网帧结构:
在这一层,请求先到达均衡器,再由均衡器将 MAC目标地址修改为真实服务器的MAC地址,如图:
网络层负载均衡
应用层负载均衡
请求离开传输层后,就无法再通过转发方式路由数据,只能通过代理方式实现,因此当请求到达应用层后,应用层的负载均衡是通过代理方式实现,如图:
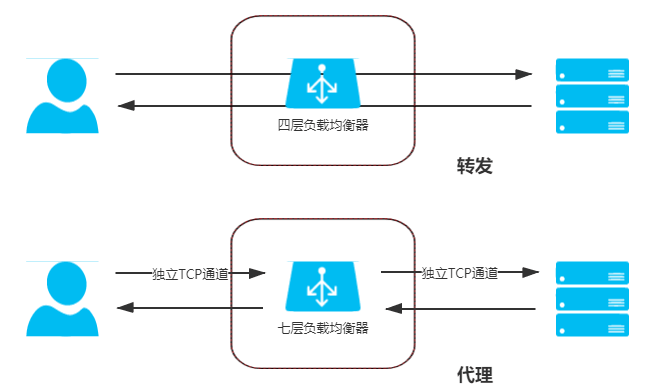
如果网站的性能瓶颈并不在于网络性能,要论整个服务集群对外所体现出来的服务性能,那么这一层均衡器可以承载更多的能力,比如:静态资源缓存、安全防护(如:DDoS)、访问控制(如:服务降级、熔断、异常注入等)。
均衡策略
轮询均衡策略 权重轮询均衡策略 随机均衡策略 权重随机均衡策略 一致性哈希均衡策略 响应速度均衡策略 最少连接数均衡策略
服务端缓存
相关信息
凤凰架构 远程服务调用 事务处理 透明多级分流系统 架构安全性
事务处理
ACID CAP 理论 BASE 理论
事务的概念虽然最初起源于数据库系统,但今天已经有所延伸,而不再局限于数据库本身了,所有需要保证数据一致性的应用场景,包括但不限于数据库、事务内存、缓存、消息队列、分布式存储,等等,都有可能会用到事务。
- 当一个服务只使用一个数据源时,通过 A、I、D 来获得一致性是最经典的做法,也是相对容易的。此时,多个并发事务所读写的数据能够被数据源感知是否存在冲突,并发事务的读写在时间线上的最终顺序是由数据源来确定的,这种事务间一致性被称为“内部一致性”。
- 当一个服务使用到多个不同的数据源,甚至多个不同服务同时涉及多个不同的数据源时,问题就变得相对困难了许多。此时,并发执行甚至是先后执行的多个事务,在时间线上的顺序并不由任何一个数据源来决定,这种涉及多个数据源的事务间一致性被称为“外部一致性”。
外部一致性问题通常很难再使用 A、I、D 来解决,因为这样需要付出很大乃至不切实际的代价;但是外部一致性又是分布式系统中必然会遇到且必须要解决的问题,为此我们要转变观念,将一致性从“是或否”的二元属性转变为可以按不同强度分开讨论的多元属性,在确保代价可承受的前提下获得强度尽可能高的一致性保障,也正因如此,事务处理才从一个具体操作上的“编程问题”上升成一个需要全局权衡的“架构问题”。
注
凤凰架构
分布式架构中出现的问题,如注册发现、跟踪治理、负载均衡、传输通信等,既可以由硬件实现,也可以由软件实现:
硬件层面的解决方案
- 某个系统需要伸缩扩容,通常会购买新的服务器,部署若干副本实例来分担压力;
- 如果某个系统需要解决负载均衡问题,通常会布置负载均衡器,选择恰当的均衡算法来分流;
- 如果需要解决传输安全问题,通常会布置 TLS 传输链路,配置好 CA 证书以保证通信不被窃听篡改;
- 如果需要解决服务发现问题,通常会设置 DNS 服务器,让服务访问依赖稳定的记录名而不是易变的 IP 地址。
软件层面的解决方案:
| Kubernetes | Spring Cloud | |
|---|---|---|
| 弹性伸缩 | Autoscaling | N/A |
| 服务发现 | KubeDNS / CoreDNS | Spring Cloud Eureka |
| 配置中心 | ConfigMap / Secret | Spring Cloud Config |
| 服务网关 | Ingress Controller | Spring Cloud Zuul |
| 负载均衡 | Load Balancer | Spring Cloud Ribbon |
| 服务安全 | RBAC API | Spring Cloud Security |
| 跟踪监控 | Metrics API / Dashboard | Spring Cloud Turbine |
| 降级熔断 | N/A | Spring Cloud Hystrix |
警告
凤凰架构
作为一个普通的服务开发者,作为一个“螺丝钉”式的程序员,微服务架构是友善的。可是,微服务对架构者是满满的恶意,对架构能力要求已提升到史无前例的程度,笔者在这部文档的多处反复强调过,技术架构者的第一职责就是做决策权衡,有利有弊才需要决策,有取有舍才需要权衡,如果架构者本身的知识面不足以覆盖所需要决策的内容,不清楚其中利弊,恐怕也就无可避免地陷入选择困难症的困境之中。
SOA 在 21 世纪最初的十年里曾经盛行一时,有 IBM 等一众行业巨头厂商为其呐喊冲锋,吸引了不少软件开发商、尤其是企业级软件的开发商的跟随,最终却还是偃旗息鼓,沉寂了下去。在稍后的远程服务调用一节,笔者会提到 SOAP 协议被逐渐边缘化的本质原因:过于严格的规范定义带来过度的复杂性。而构建在 SOAP 基础之上的 ESB、BPM、SCA、SDO 等诸多上层建筑,进一步加剧了这种复杂性。开发信息系统毕竟不是作八股文章,过于精密的流程和理论也需要懂得复杂概念的专业人员才能够驾驭。SOA 诞生的那一天起,就已经注定了它只能是少数系统阳春白雪式的精致奢侈品,它可以实现多个异构大型系统之间的复杂集成交互,却很难作为一种具有广泛普适性的软件架构风格来推广。SOA 最终没有获得成功的致命伤与当年的EJB如出一辙,尽管有 Sun Microsystems 和 IBM 等一众巨头在背后力挺,EJB 仍然败于以 Spring、Hibernate 为代表的“草根框架”,可见一旦脱离人民群众,终究会淹没在群众的海洋之中,连信息技术也不曾例外过。
相关信息
架构演进:
- 原始分布式时代
- 单体系统时代
- SOA 时代
- 烟囱式架构
- 微内核架构(又称:插件式架构)
- 事件驱动架构
- 微服务时代
- 后微服时代
- 基于 Spring Cloud 的微服务架构
- 基于 Kubernetes 的微服务架构
- 服务网格(Service Mesh) 的边车代理模式(Sidecar Proxy)
- 无服务时代
相关信息
分层架构在软件领域无处不在!
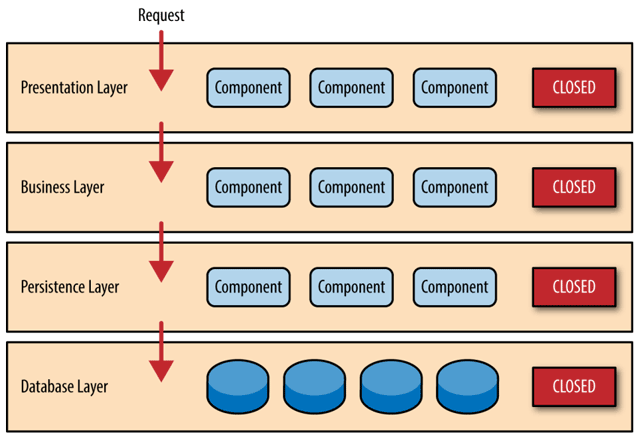
分层架构(Layered Architecture)已是现在几乎所有信息系统建设中都普遍认可、采用的软件设计方法,无论是单体还是微服务,抑或是其他架构风格,都会对代码进行纵向层次划分,收到的外部请求在各层之间以不同形式的数据结构进行流转传递,触及最末端的数据库后按相反的顺序回馈响应,如图 1-1 所示。对于这个意义上的“可拆分”,单体架构完全不会展露出丝毫的弱势,反而可能会因更容易开发、部署、测试而获得一些便捷性上的好处。
重要
凤凰架构
UNIX 分布式设计哲学:保持接口与实现的简单性,比系统的任何其他属性,包括准确性、一致性和完整性,都来得更加重要。
提示
SpringBoot Nacos
通过 Naocs 发现中心的命名空间 namespace 和 分组 group 参数对服务实例进行环境隔离,这种配置的设置对接口调试非常有帮助。
基于 IDEA 可以通过启动参数进行统一配置:
spring.cloud.nacos.discovery.namespace=zzn;spring.profiles.active=dev;spring.cloud.nacos.discovery.group=zzn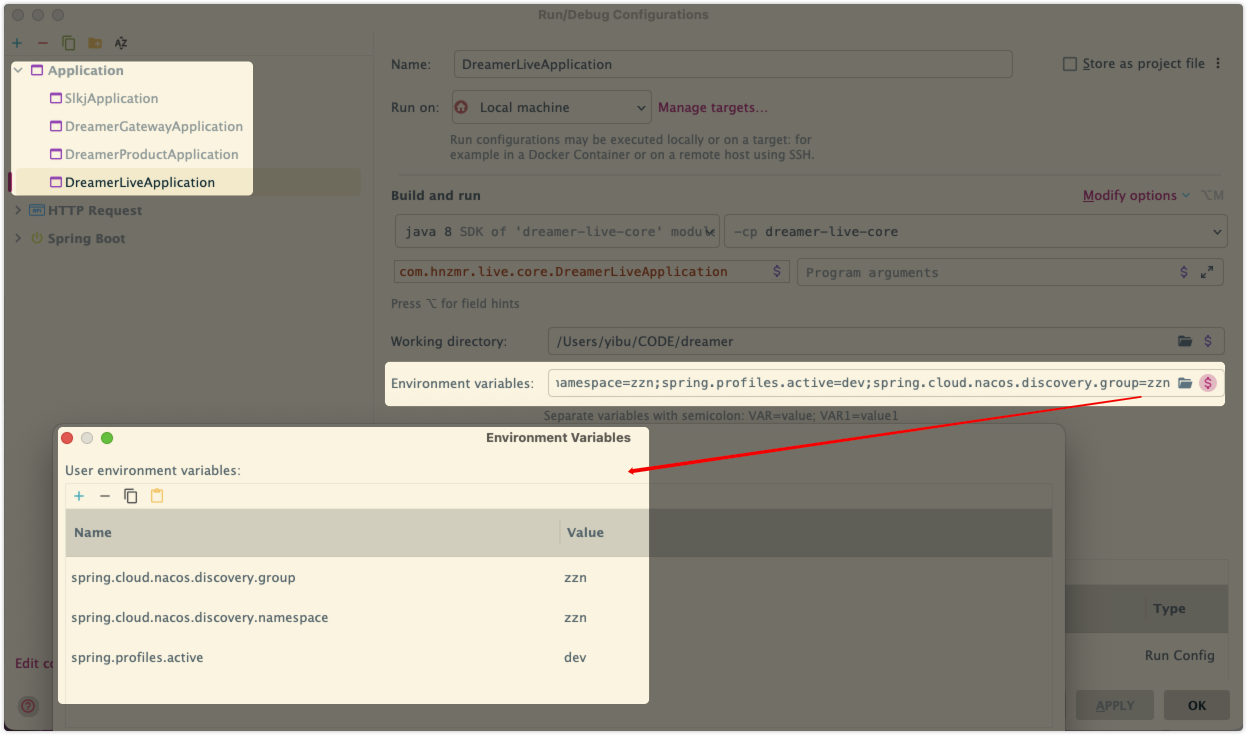
重要
在微服务环境中必然会面临的服务发现、远程调用、负载均衡、集中配置等非功能性的需求。
注
凤凰架构
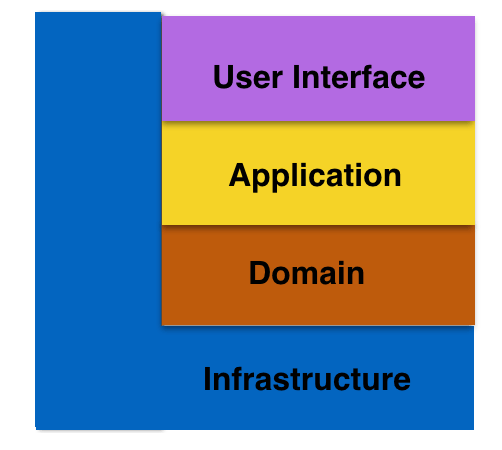
小书店 Fenix's Bookstore 的架构演进:
单体架构:
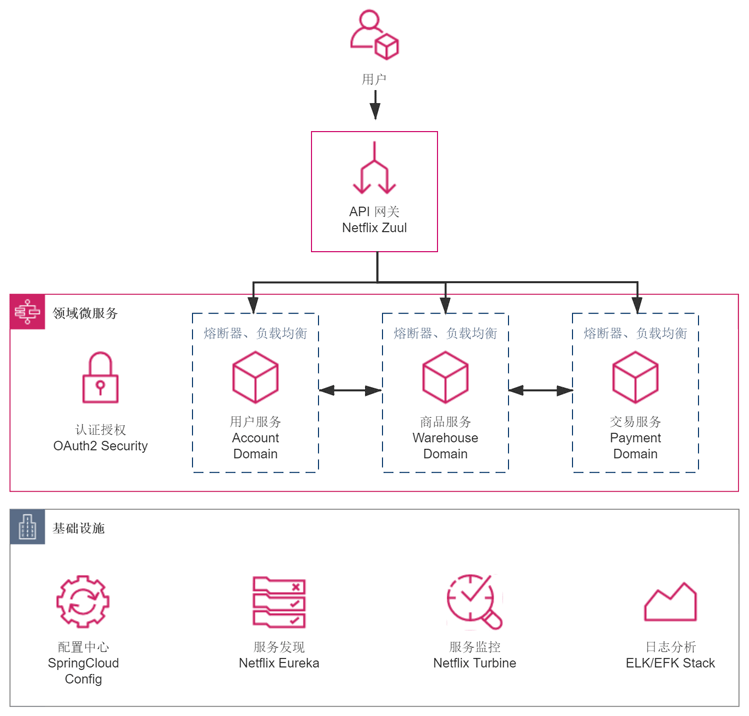
基于 Spring Cloud 的微服务架构:
- 优势:解决扩容缩容、独立部署、运维和管理等问题
- 劣势:对于团队的开发人员、设计人员、架构人员来说,并没有感觉到工作变得轻松,微服务中的各种新技术名词,如配置中心、服务发现、网关、熔断、负载均衡等等,就够一名新手学习好长一段时间;从产品角度来看,各种 Spring Cloud 的技术套件,如 Config、Eureka、Zuul、Hystrix、Ribbon、Feign 等,也占据了产品的大部分编译后的代码容量。
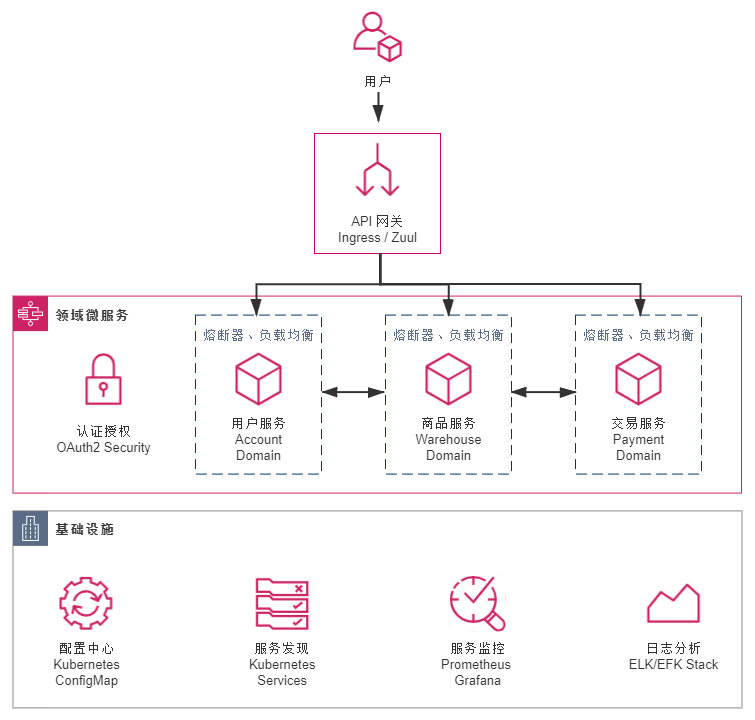
基于 Kubernetes 的微服务架构:
- 优势:充分享受虚拟化技术发展红利,应用可以灵活地扩容、缩容,不再畏惧单个服务的崩溃消亡。
- 劣势:光靠着 Kubernetes 本身的虚拟化基础设施,难以做到精细化的服务治理,譬如熔断、流控、观测,等等;而即使是那些它可以提供支持的分布式能力,譬如通过 DNS 与服务来实现的服务发现与负载均衡,也只能说是初步解决了的分布式中如何调用服务的问题而已,只靠 DNS 难以满足根据不同的配置规则、协议层次、均衡算法等去调节负载均衡的执行过程这类高级的配置需求。Kubernetes 提供的虚拟化基础设施是我们尝试从应用中剥离分布式技术代码踏出的第一步,但只从微服务的灵活与可控这一点而言,基于 Kubernetes 实现的版本其实比上一个 Spring Cloud 版本里用代码实现的效果(功能强大、灵活程度)是有所倒退的,这也是当时我们未放弃 Hystrix、Spring Security OAuth 2 等组件的原因。
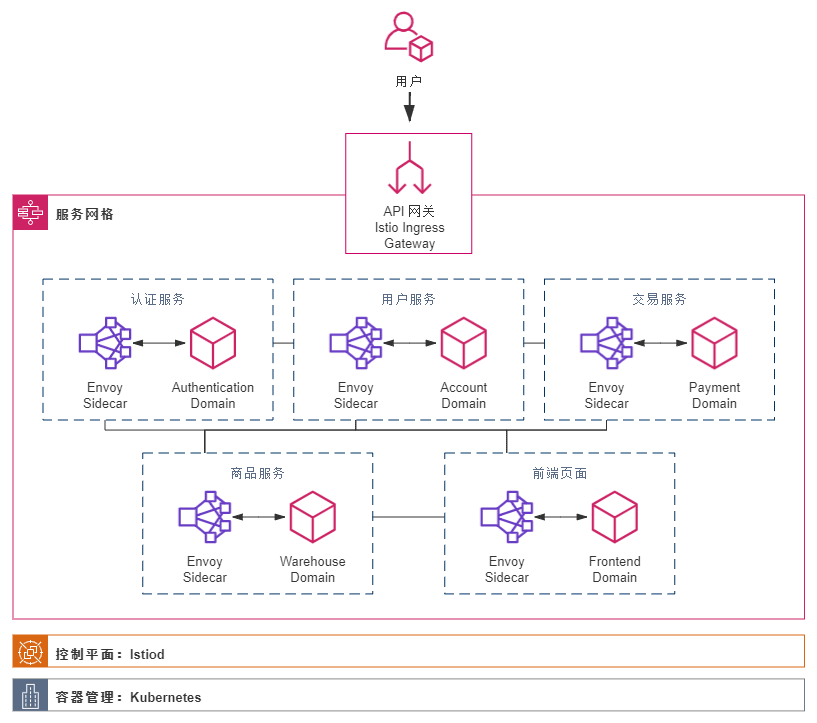
基于 Istio 的服务网格架构:
- 优势:把“选择什么通信协议”、“怎样调度流量”、“如何认证授权”之类的技术问题隔离于程序代码之外,取代今天 Spring Cloud 全家桶中大部分组件的功能,微服务只需要考虑业务本身的逻辑,这才是最理想的Smart Endpoints解决方案。
- 劣势:在 2018 年才火起来,今天它仍然是个新潮的概念,仍然未完全成熟。
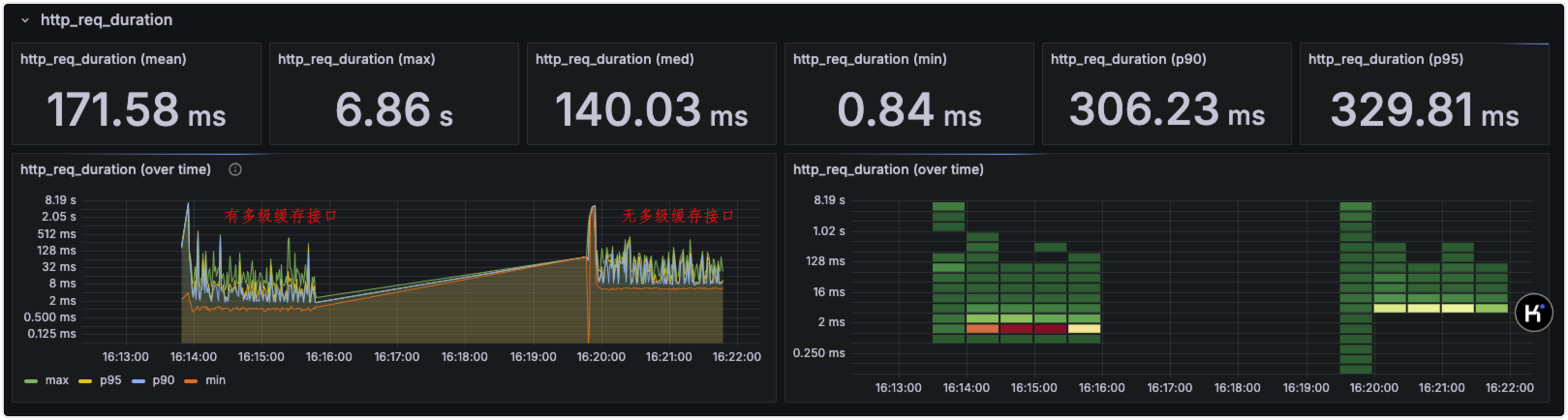
注
k6
接口压测对比结论:有多级缓存的响应速度是无多级缓存的 6 倍左右,即响应速度更快,因此在高并发场景下,多级缓存策略是必要的。
对应示例代码:
// 有多级缓存策略
public List<FirepowerInfoDO> listAllByMultiLevelCache() {
List<FirepowerInfoDO> items = Lists.newArrayList();
long start = System.currentTimeMillis();
items = LocalCache.get(LOCAL_CACHE_KEY);
if (CollectionUtil.isNotEmpty(items)) {
log.info(LOG + "本地缓存取数,耗时:{}(ms)", System.currentTimeMillis() - start);
return items;
}
if (redisTemplate.hasKey(REDIS_CACHE_KEY)) {
String giftCache = (String) redisTemplate.opsForValue().get(REDIS_CACHE_KEY);
items = JSON.parseArray(giftCache, FirepowerInfoDO.class);
log.info(LOG + "Redis缓存取数,耗时:{}(ms)", System.currentTimeMillis() - start);
LocalCache.put(LOCAL_CACHE_KEY, items);
return items;
}
items = this.list();
sync2MultiLevelCache("获取火力值信息列表(多级缓存)", items);
log.info(LOG + "数据库取数,耗时:{}(ms)", System.currentTimeMillis() - start);
return items;
} // 无多级缓存策略
public List<FirepowerInfoDO> listAll() {
return this.list();
}相关信息
并发
并发相关术语:线程、进程、多线程、并发与并行、同步与异步、死锁、虚拟线程(JDK21)、JAVA内存模型(JMM)、volatile关键字、乐观锁与悲观锁、CAS算法、synchronized关键字、公平锁与非公平锁、共享锁与独占锁、ThreadLocal类、线程池(池化技术)、Future、抽象队列同步器AQS(AbstractQueuedSynchronizer)、虚拟线程、Executor 与 ThreadPoolExecutor。
重要
Java String 最佳实践
String 实践原则
String、StringBuilder、StringBuffer 在日常开发中属于高频使用的类,具体用哪个,要遵守以下原则:
原则1:操作少量的数据: 适用 String
原则2:单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
原则3:多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
简言之:一看数据量、二看线程数
相关信息
SpringBoot 2.3.4.RELEASE RabbitMQ 3.12.14 Erlang 25.3.2.13
实现自动提交(ACK)+有限次重试+死信队列存储消费失败消息,思路:
yml配置文件配置 rabbitmq 属性、死信相关的路由键、交换区以及队列- 基于 JavaConfig 类的配置(如:RabbitGiftConsumptionConfig.java),需配置重试策略
- 基于 JavaConfig 类的配置(如:RabbitGiftConsumptionConfig.java),需在 @RabbitListener#containerFactory 声明中指定自定义配置类
- 编写业务队列监听方法,如:GiftPresentConsumptionListener#
- 编写死信队列监听方法
- 流程验证
示例代码:
一、配置文件
spring:
# rabbitmq
rabbitmq:
host: ***********
port: 5672
username: dreamer
password: dreamer
virtual-host: /dreamer
# 生产者 ==> EXCHANGE 确认方式
publisher-confirm-type: correlated
# EXCHANGE ===> QUEUE 返回类型
publisher-returns: true
listener:
simple:
# 自动确认模式
acknowledge-mode: auto
# 决定由于监听器抛出异常而拒绝的消息是否被重新放回队列。默认值为 true,重新放回队列。这里设置为 false,如果多次重试还是异常就转发到死信队列
default-requeue-rejected: false
# 配置重试
retry:
# 开启重试
enabled: true
# 消息最多重试5次
max-attempts: 5
# 消息多次消费的间隔2秒
initial-interval: 2000
# 最大允许重试时间
max-interval: 30000
# 下一次重试的时间间隔 = 上次重试时间间隔 * multiplier
multiplier: 2二、配置类
package com.hnzmr.product.core.config;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.config.RetryInterceptorBuilder;
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.retry.RejectAndDontRequeueRecoverer;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.interceptor.RetryOperationsInterceptor;
@Slf4j
@Data
@Configuration
public class RabbitGiftConsumptionConfig {
public static final String LOG = "[礼物打赏消费配置类]";
@Value("${product.gift.consumption.routingkey}")
private String productGiftConsumptionRoutingkey;
@Value("${product.fanout.exchange}")
private String productFanoutExchange;
@Bean
public Exchange giftConsumptionQueueExchange() {
return new FanoutExchange(productFanoutExchange);
}
@Autowired
CachingConnectionFactory cachingConnectionFactory;
/**
* *************************************************
* ********** 礼物打赏2.0队列配置 ********************
* *************************************************
*/
/**
* Version:打赏2.0
* 礼物赠送队列(从礼物界面送出的)
*/
@Value("${product.gift.consumption.presentQueue}")
private String productGiftConsumptionPresentQueue;
/**
* 最大重试次数
*/
@Value("${spring.rabbitmq.listener.simple.retry.max-attempts}")
private Integer retryMaxAttempts;
/**
* 初始重试时间
*/
@Value("${spring.rabbitmq.listener.simple.retry.initial-interval}")
private Integer retryInitialInterval;
/**
* 最大重试时间
*/
@Value("${spring.rabbitmq.listener.simple.retry.max-interval}")
private Integer retryMaxInterval;
/**
* 重试时间因子
*/
@Value("${spring.rabbitmq.listener.simple.retry.multiplier}")
private Integer retryMultiplier;
/**
* 死信交换机
*/
public static final String X_DEAD_LETTER_EXCHANGE = "x-dead-letter-exchange";
/**
* 死信路由键
*/
public static final String X_DEAD_LETTER_ROUTING_KEY = "x-dead-letter-routing-key";
@Bean
public Queue giftConsumptionPresentQueue() {
// 绑定死信队列
return QueueBuilder.durable(productGiftConsumptionPresentQueue)
.withArgument(X_DEAD_LETTER_EXCHANGE, deadLetterExchange)
.withArgument(X_DEAD_LETTER_ROUTING_KEY, deadLetterRoutingKey)
.build();
}
@Bean
public Binding giftConsumptionPresentBinding() {
return BindingBuilder.bind(giftConsumptionPresentQueue())
.to(giftConsumptionQueueExchange())
.with(productGiftConsumptionRoutingkey).noargs();
}
@Bean
SimpleRabbitListenerContainerFactory giftPresentConsumerContainerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(cachingConnectionFactory);
factory.setAcknowledgeMode(AcknowledgeMode.AUTO);
factory.setMessageConverter(new Jackson2JsonMessageConverter());
// 配置并发线程数
factory.setConcurrentConsumers(10);
// 配置重试策略
factory.setAdviceChain(retryInterceptor());
return factory;
}
@Bean
public RetryOperationsInterceptor retryInterceptor() {
RetryOperationsInterceptor retryOperationsInterceptor = RetryInterceptorBuilder.stateless()
.maxAttempts(retryMaxAttempts)
.backOffOptions(retryInitialInterval, retryMultiplier, retryMaxInterval)
.recoverer(new RejectAndDontRequeueRecoverer())
.build();
log.info(LOG + "重试策略:max-attempts=[{}];initial-interval=[{}];max-interval=[{}];multiplier=[{}]"
, retryMaxAttempts, retryInitialInterval, retryMaxInterval, retryMultiplier);
return retryOperationsInterceptor;
}
/**
* *************************************************
* ********** 礼物打赏死信队列配置 ********************
* *************************************************
*/
@Value("${app.rabbitmq.exchange.common-dead-letter}")
private String deadLetterExchange;
@Value("${app.rabbitmq.queue.gift-present-dead-letter}")
private String deadLetterQueue;
@Value("${app.rabbitmq.routingKey.gift-present-dead-letter}")
private String deadLetterRoutingKey;
/**
* 死信交换机
*
* @return
*/
@Bean
public Exchange deadLetterExchange() {
return new DirectExchange(deadLetterExchange);
}
/**
* 死信队列
*
* @return
*/
@Bean
public Queue dealLetterQueue() {
return new Queue(deadLetterQueue);
}
/**
* 死信队列与死信交换机绑定
*
* @return
*/
@Bean
public Binding localDealLetterBinding() {
return BindingBuilder.bind(dealLetterQueue()).to(deadLetterExchange())
.with(deadLetterRoutingKey).noargs();
}
}三、监听消费
package com.hnzmr.product.core.listener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
/**
* @program: dreamer
* @description: 送礼消费监听
* @author: zzn
* @create: 2024-11-25 14:23
**/
@Slf4j
@Component
public class GiftPresentConsumptionListener {
@RabbitListener(
queues = "#{@rabbitGiftConsumptionConfig.productGiftConsumptionPresentQueue}"
, containerFactory = "giftPresentConsumerContainerFactory"
)
@Transactional(rollbackFor = Exception.class)
public void listenPersistQueue(Message msg) throws Exception {
// 上锁
// 1. 参数合规校验
// 2. 数据幂等校验
// 3. 业务数据处理
// 4. 失败异常抛出触发重试机制
// 解锁
// ...
}
@RabbitListener(
queues = "#{@rabbitGiftConsumptionConfig.deadLetterQueue}"
)
@Transactional(rollbackFor = Exception.class)
public void DeadLetterListener(Message msg) throws Exception {
// 处理消费失败的消息....
}
}相关信息
SpringBoot RabbitMQ
SpringBoot 完全整合 RabbitMQ + 100% 发送消息 + 高可靠消费消息 + 源码解析
采用自动ACK+有限次重试+推送到死信队列的方式存储消费异常的消息。
相关信息
理论基础 数据库 事务
事务:对数据持久化时,事务保障了持久化操作满足:“要么全部执行成功,要么全部不执行”的原则。
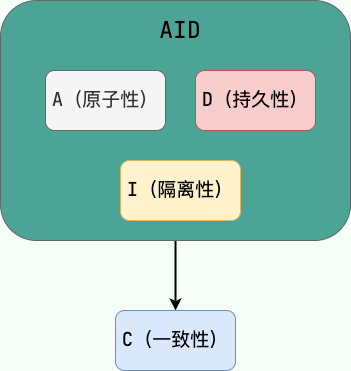
四大特性:A C I D
- 原子性(A):事务不可再分
- 一致性(C):执行事务后,数据一致
- 隔离性(I) :事务之间互不干扰
- 持久性(D):事务提交后,数据即持久化成功
AID是手段,C是目的,即只有保证了事务的AID后,D才能得到保障:
相关信息
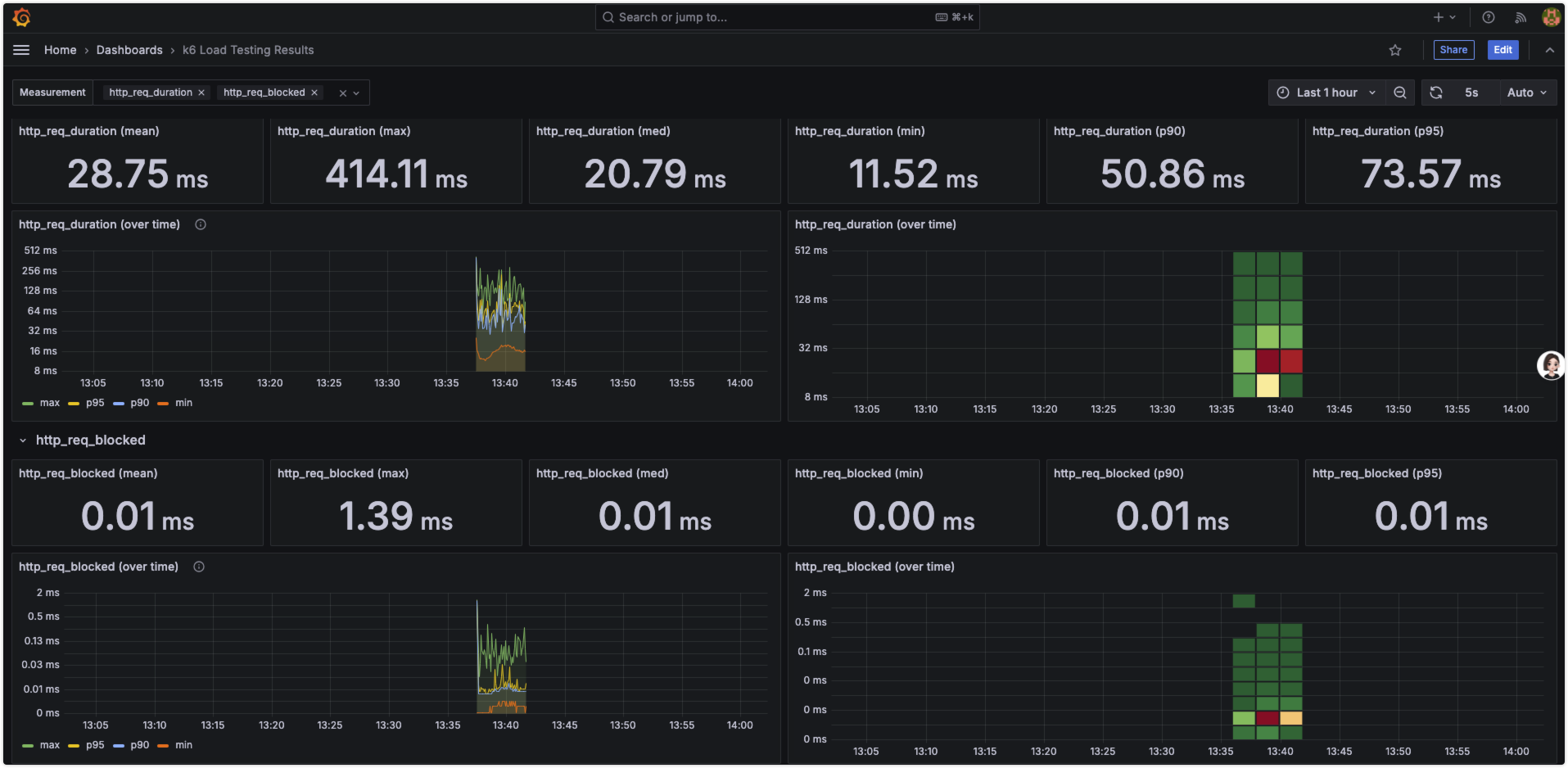
Docker k6 Grafana InfluxDB
基于 K6 压测接口挺好用。

相关信息
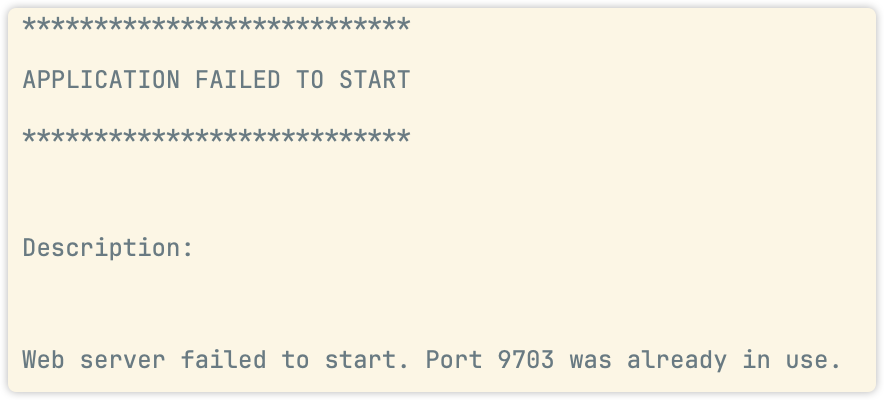
Mac SpringBoot 通用
遇到 Web server failed to start. Port 9703 was already in use.
可执行以下命令杀死进程:
lsof -i :9703
kill -9 <PID>如:
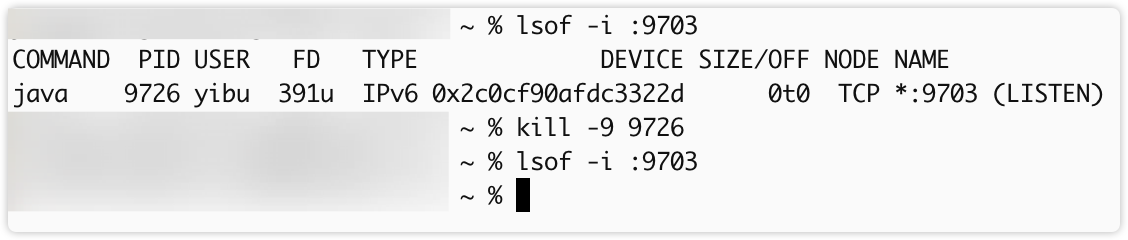
执行完后,重启 SpringBoot 工程。
其他场景下的端口占用,同样适用。
相关信息
数据库理论基础 并发事务 事务传播级别
并发事务(超过2个事务操作数据)引起脏读、幻读、不可重复读、丢失更新4类问题,这4类问题可以通过设置事务传播级别解决,共有4类级别,从低到高依次为:读未提交、读已提交、可重复读、可串行化,他们对数据库性能的影响如下:
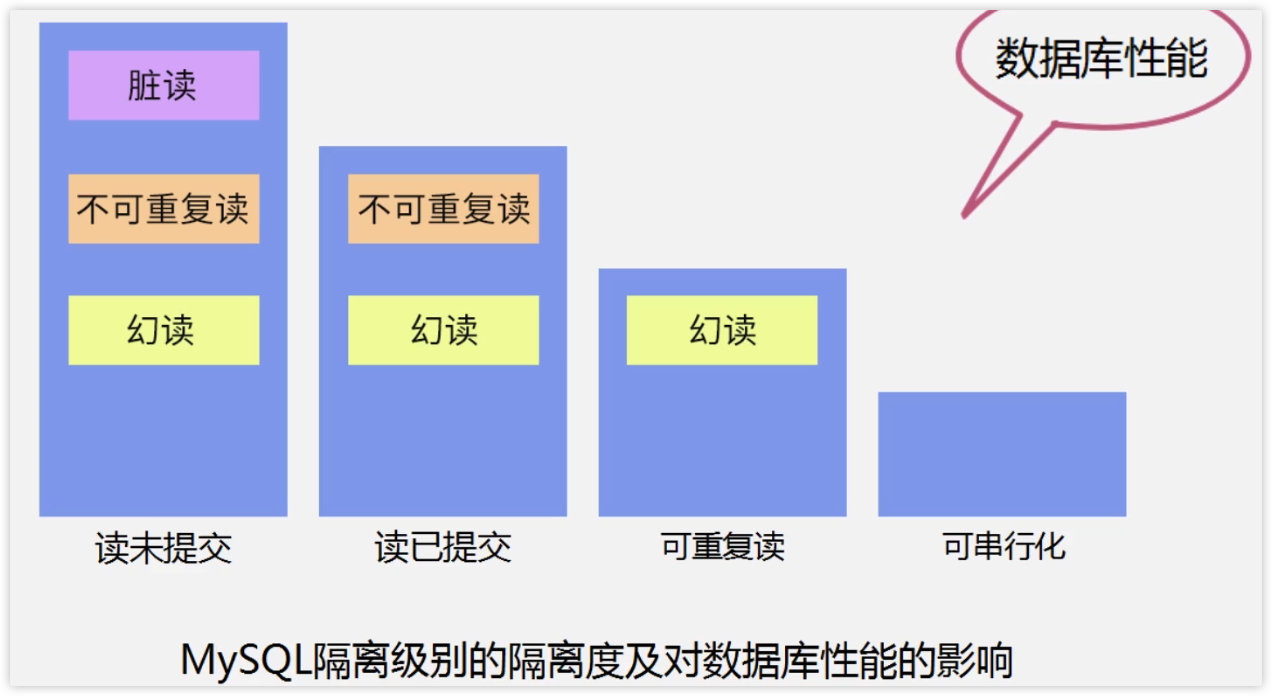
当遇到事务并发问题时,可以尝试从以下几方面着手排查:
- 无数据一致性要求
- 只有查询的事务
- 事务中有统计汇总
- 内容繁杂的大失误
注意
高并发 数据一致性 事务传播 锁粒度设计
并发场景下,发现数据库写入数据不一致时,可以考虑是否是事务传播级别引起的,此外其他可能引起数据不一致的:
- 未加锁或锁设计不合理导致多线程并发修改导致数据不一致
11月日志
相关信息
Java SpringBoot
通过以下代码块模拟程序异常场景:
// X0% 的概率进入 1/0
if (new Random().nextInt(10) < 9) {
log.error(LOG + "命中异常分支...");
int i = 1 / 0;
} if (new Random().nextInt(10) < 5) {
throw new InterruptedException("命中异常分支。。。InterruptedException");
}else if(new Random().nextInt(10) < 5){
throw new RuntimeException("命中异常分支。。。InterruptedException");
}异常场景主要用于验证代码的健壮性,如:异常回滚等。
相关信息
IntelliJ IDEA SpringBoot
MyBatis配置输出SQL:
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl配合 IDEA MyBatis Log Free 插件查看SQL输出
警告
spring-boot-starter-amqp:2.3.4.RELEASE
RabbitMQ 3.12.14
Erlang 25.3.2.13
rabbitmq 消费端消费失败后,需考虑重试机制。
引入重试机制后需考虑消息重复消费问题,确保数据幂等。
此外,重试策略要选好,避免短时间内产生大量重试请求,造成系统压力和消息堆积,重试到一定次数后仍未成功的,需把消息推送到死信队列做进一步处理。
注意,对于数据一致性要求高的场景,如:与钱袋子💰相关的,建议使用手动ACK模式,确保消息处理的准确性。
注意
Docker 拉取镜像慢时,需配置可访问的第三方镜像,如:
{
"registry-mirrors": [
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://pee6w651.mirror.aliyuncs.com"
]
}配置后,需要重载文件、重启Docker服务
提示
Docker 常用镜像的启动参数得懂,比如启动 MySQL:
docker run -d --restart=always --name mysql \
-v /datas/mysql/data:/var/lib/mysql \
-v /datas/mysql/conf:/etc/mysql \
-v /datas/mysql/log:/var/log/mysql \
-p 3306:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=root \
mysql:5.6 \
--character-set-server=utf8mb4 \
--collation-server=utf8mb4_general_ci-v /datas/mysql/data:/var/lib/mysql:将数据文件夹挂载到主机
-v /datas/mysql/conf:/etc/mysql:将配置文件夹挂在到主机,可以在宿主机放一份自定义 my.cnf文件,那么容器就会按自定义配置启动
-v /datas/mysql/log:/var/log/mysql:将日志文件夹挂载到主机
-p 3306:3306:将容器的3306端口映射到主机的3306端口
-e MYSQL_ROOT_PASSWORD=root:初始化root用户的密码
--character-set-server=utf8mb4:设置字符集
--collation-server=utf8mb4_general_ci:排序方式提示
可以在 Win/Mac 下同时配置 Github、Gitee,也可以一个项目管理同时关联Gitee、Github库
10月日志
警告
监控告警平台 不好用
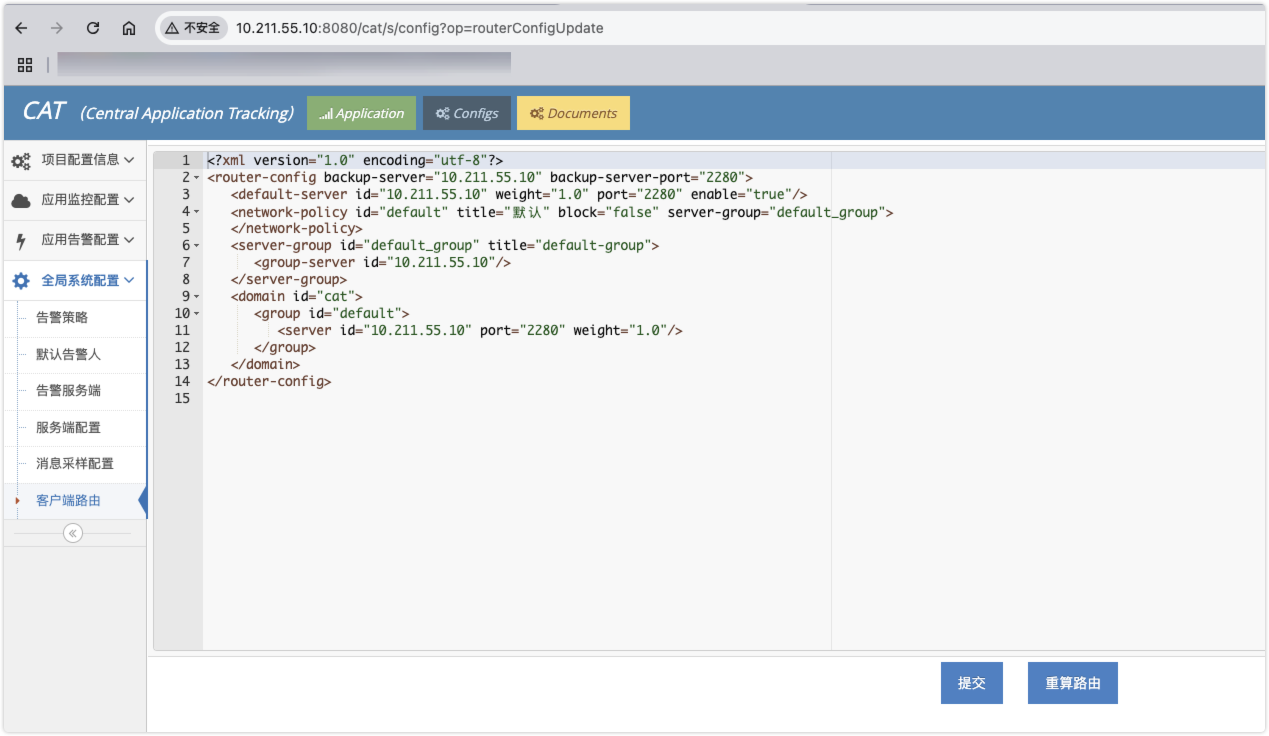
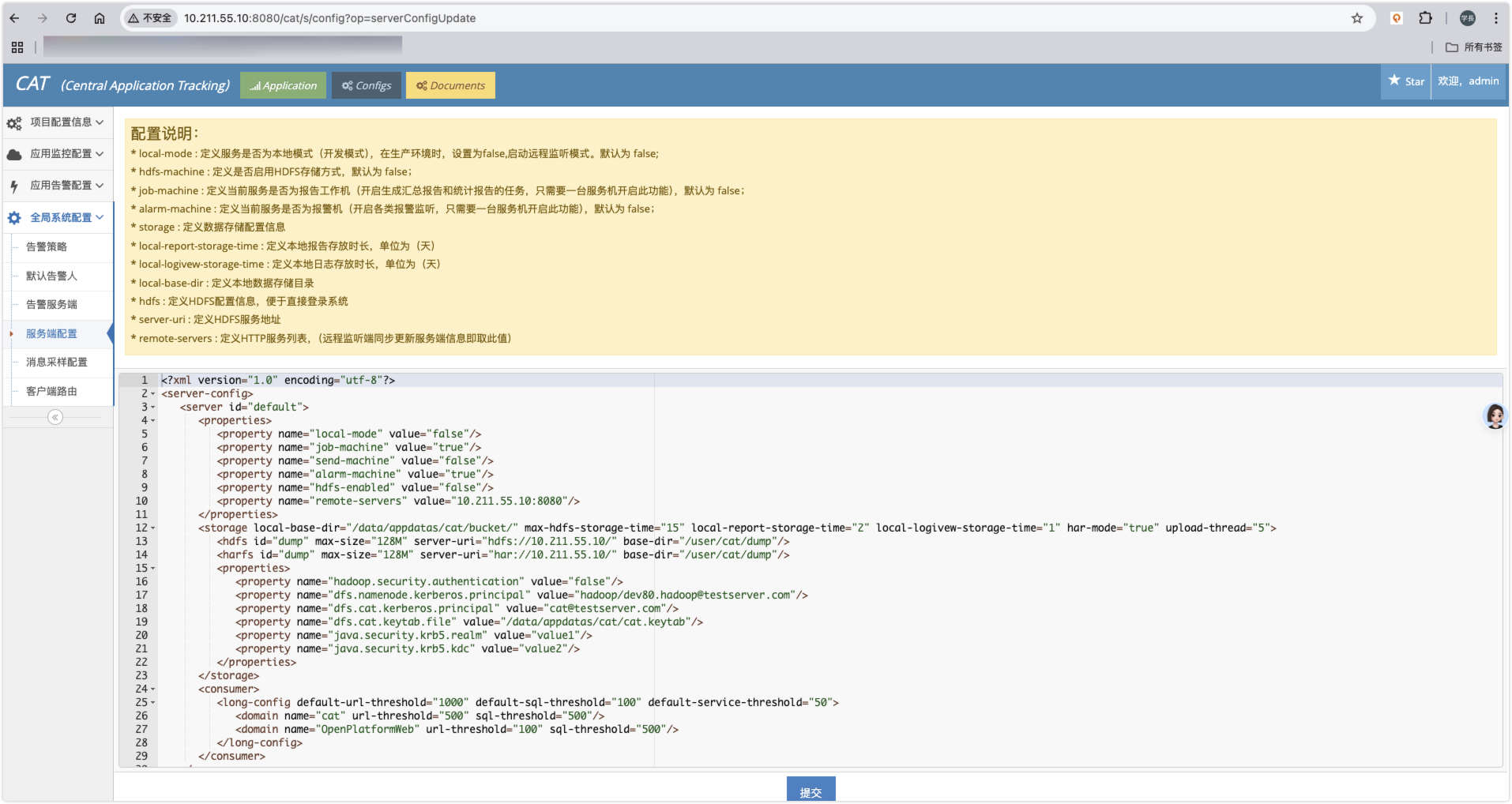
CAT 是基于 Java 开发的实时应用监控平台,为美团点评提供了全面的实时监控告警服务。
CAT 成功部署并访问,环境如下:
- 虚拟机 Linux Centos8
[root@localhost cat]# uname -a
Linux localhost.localdomain 4.18.0-348.7.1.el8_5.x86_64 #1 SMP Wed Dec 22 13:25:12 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux- JAVA8
[root@localhost cat]# java -version
java version "1.8.0_431"
Java(TM) SE Runtime Environment (build 1.8.0_431-b10)
Java HotSpot(TM) Server VM (build 25.431-b10, mixed mode)- Tomcat7
[root@localhost tomcat]# ls
apache-tomcat-7.0.99.tar.gz tomcat7- Maven3
[root@localhost tomcat]# mvn -v
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/maven/apache-maven-3.6.3
Java version: 1.8.0_431, vendor: Oracle Corporation, runtime: /usr/java/jdk1.8.0_431/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "4.18.0-348.7.1.el8_5.x86_64", arch: "i386", family: "unix"- 环境准备完毕后,将
cat.war放置在这个路径下: war包下载地址
[root@localhost webapps]# pwd
/opt/tomcat/tomcat7/webapps
[root@localhost webapps]# ls
cat cat.war docs examples host-manager manager ROOT
[root@localhost webapps]#- 启动 CAT 服务:
-- 进入 Tomcat7 bin 目录
[root@localhost bin]# pwd
/opt/tomcat/tomcat7/bin
-- 执行 sh catalina.sh
[root@localhost bin]# sh catalina.sh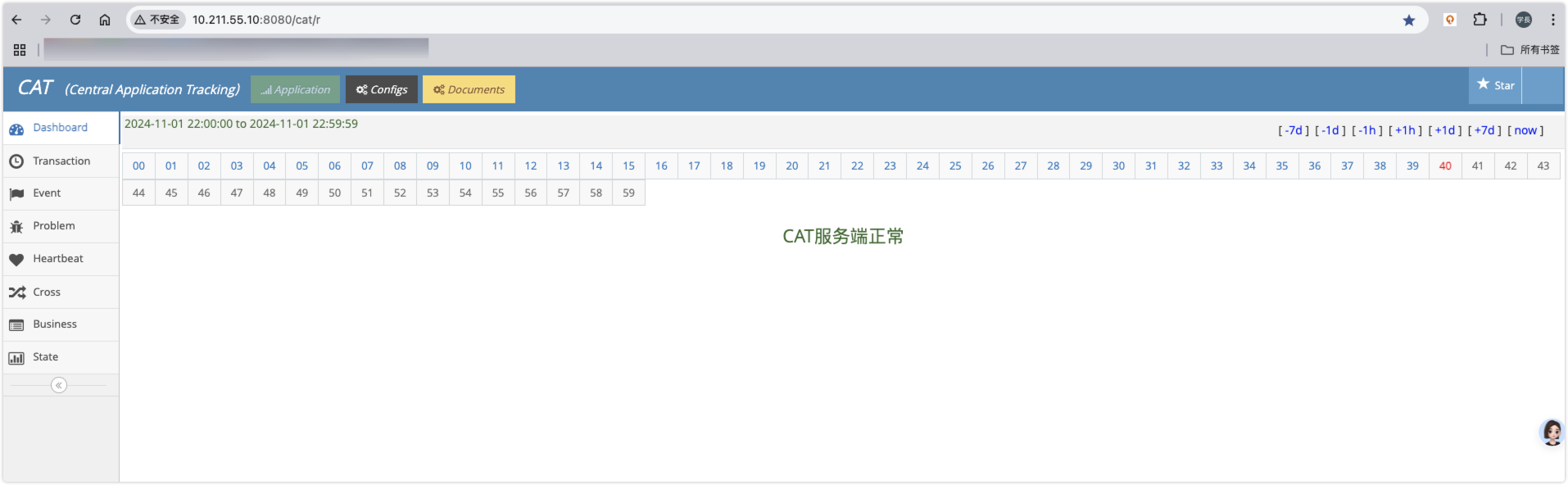
访问配置管理界面: