MySQL
参考
🔗 数据库内核月报 📝 阿里巴巴
📚 《Alibaba Java 开发手册》 📝 ch5 MySQL 数据库
存储引擎
- InnoDB,支持事务、并发控制。
- MyISAM,适合插入和查询。
- Memory,数据存放在内存。
高性能、高可用 MySQL 架构设计
慢 SQL
定位技术
- 慢查询日志
- 服务监控
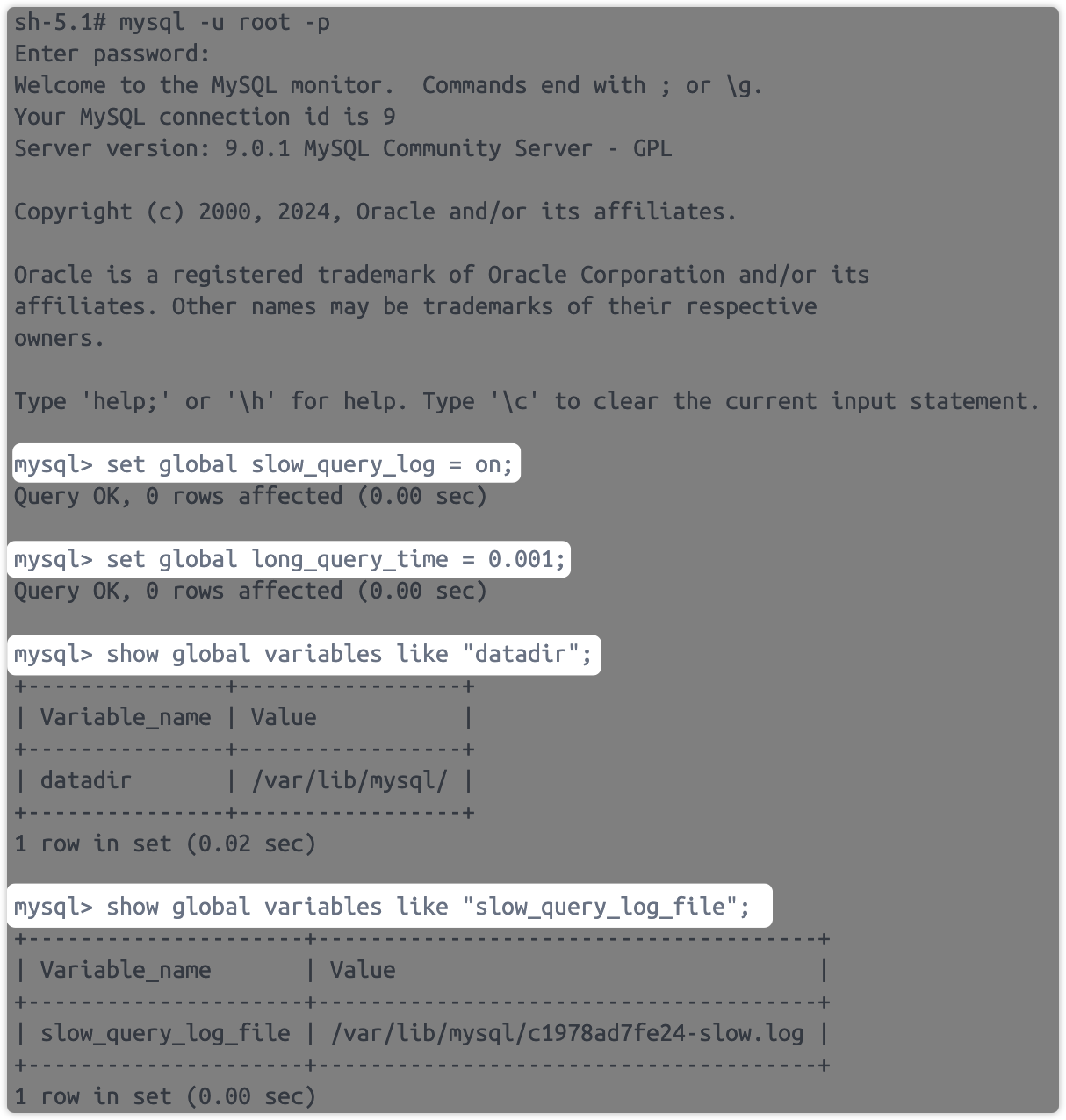
慢查询日志定位慢SQL
- 开启慢查询日志: mysql> set global slow_query_log = on;
- 设置慢查询阈值:mysql> set global long_query_time = 0.001; (时间单位:秒)
- 确定慢查询日志路径:mysql> show global variables like "datadir";
- 确定慢查询日志文件名:show global variables like "slow_query_log_file";
- 退出MySQL,在服务器中执行:tail -n5 /var/lib/mysql/c1978ad7fe24-slow.log
分析技术
使用 explain(执行计划) 分析慢 SQL。
explain + SQL 查询语句;优化手段
- 分页优化
- 索引优化
- 连接优化
- 排序优化
- Union 优化
分页优化
select * from table where type = 2 and level = 9 order by id asc limit 190289,10;优化1:延迟关联
select a.* from table a,
(select id from table where type = 2 and level = 9 order by id asc limit 190289,10 ) b
where a.id = b.id优化2:书签模式
select * from table where id >
(select * from table where type = 2 and level = 9 order by id asc limit 190索引优化 *
视情而定。
优化1:使用覆盖索引
select name from test where city='上海'被查询字段与查询条件建立联合索引:
alter table test add index idx_city_name (city, name);优化2:禁用 != 和 <>
使用 != 和 <> 会导致索引失效。
column <> 'a' 改: column > 'a' or column < 'a'优化3:使用前缀索引
alter table test add index index2(email(6));SQL JOIN
一图看懂 SQL 的所有连接,从韦恩图视角理解左连接、右连接、内连接等。
索引详解(重点)
- 优点:在数据达到一定量时,索引可加快数据检索速度,减少IO次数
- 缺点:需要额外的存储空间维护索引,同时,进行数据更新操作时,索引结构也会发生相应变化,继而影响SQL执行效率,此外,在表数据量不大时,索引未必优于全表扫描。
主要以这篇文章为主,重点了解以下内容:
- 了解索引的优缺点
- 熟悉索引的底层数据结构
- 熟练掌握索引的分类及其应用场景
- 索引的最佳实践原则
其中,索引底层数据结构的选型,需要搞清楚为什么是选择 B树 和 B+树 结构而非其他数据结构:
HASH结构。不支持顺序和范围查询,因为数据是离散分布的。
二叉查找树(Binary Search Tree)。容易从平衡树退化成斜树(线性链表)进而导致查询效率急剧下降
自平衡二叉查找树(AVL)。频繁进行旋转操作以保持平衡,增加额外开销;查询数据散列在多个节点时,会进行多次磁盘IO操作。
红黑树。与AVL树的区别在于不追求严格的平衡,而是大致平衡。
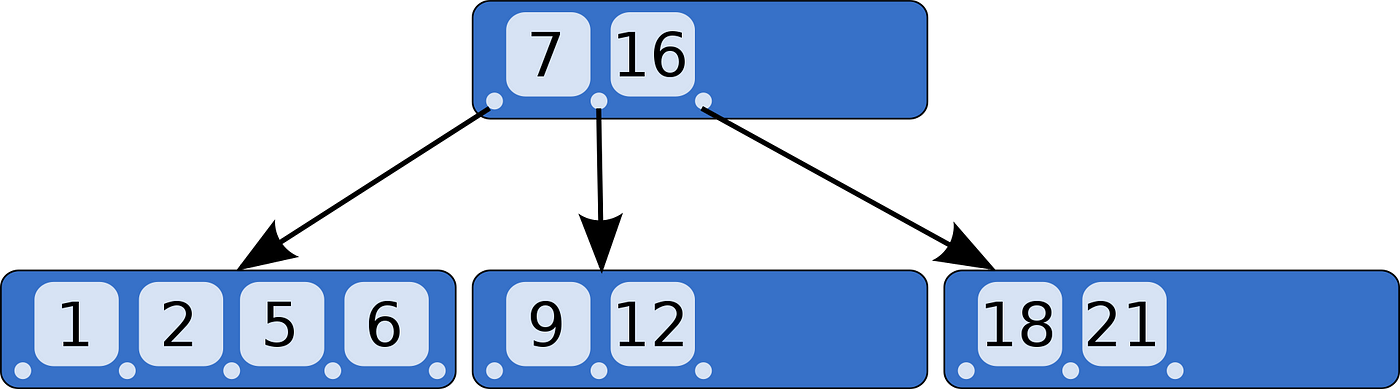
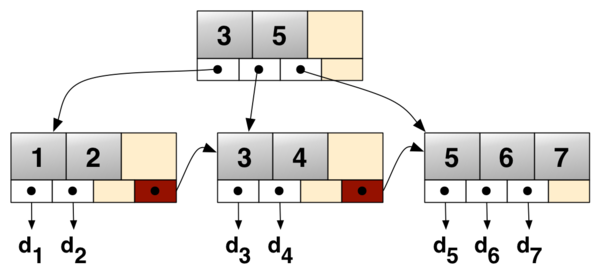
B树 & B+树 (多路平衡查找树)。B树的所有节点既存放键(KEY)也存放数据(DATA)。B+树只有叶子节点存放键(KEY)和数据(DATA),其余节点只放键(KEY)。
B树与B+树
使用原则
索引原则 *
- 原则1:业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
- 原则2:超过三章表禁止使用 join ,外键的数据类型保持绝对一致,且有索引。
- 原则3:页面搜索禁止使用左模糊或全模糊,如需要走搜索引擎解决。
- 原则4:使用
order by时,注意索引的有序性。
SQL 原则 *
- 原则1:不要用
count(列名)和count(常量)代替count(*), 在统计行数上,count(*)会统计值为 NULL 的行。 - 原则2:多表查询或变更时,需使用别名限定表名,如
table_first as t1 - 原则3:禁止使用存储过程,原因有三:难调试、难扩展、不可移植。
- 原则4:在分布式、高并发集群场景下,禁止使用外键和级联。
- 原则5:代码分页逻辑,先 count 后 page ,若 count=0 , 则直接返回。
索引分类
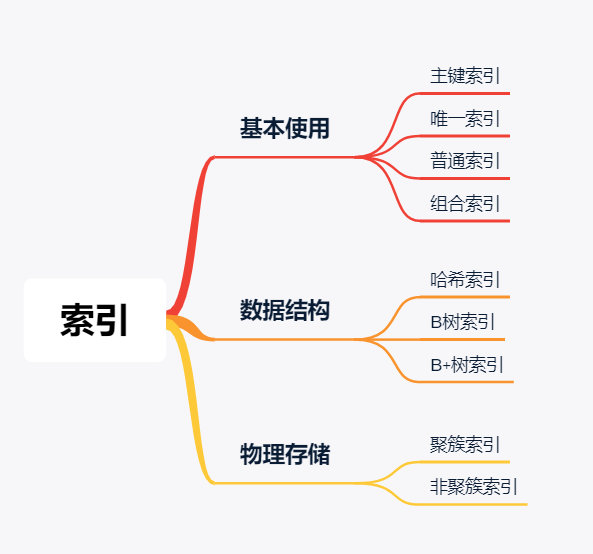
索引建立
索引失效
索引失效的 5 种情况 :
- 隐式类型转换
- 表达式计算
- 操作符判断,如
!=、>、<、<=、or、in、is null、is not null - 函数
like %XXX或like %XXX%- 联合索引不满足最左匹配原则
索引失效的**原因**:
- 索引列与索引树结构匹配失败,导致触发**回表查询**。
事务,为解决数据一致性而生。
事务
事务作用
对数据持久化时,事务保障了持久化操作满足:“要么全部执行成功,要么全部不执行”的原则。
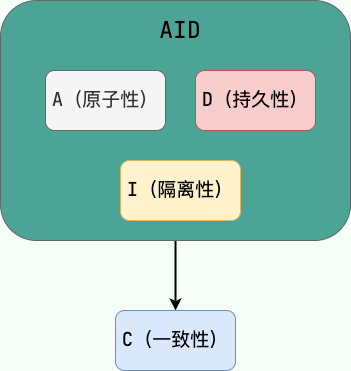
事务特性
简记:各持一元
- 原子性(A):事务不可再分
- 一致性(C):执行事务后,数据一致
- 隔离性(I) :事务之间互不干扰
- 持久性(D):事务提交后,数据即持久化成功
AID是手段,C是目的,即只有保证了事务的AID后,D才能得到保障:
并发事务
在事务并发中(超过2个事务操作数据),可能导致4类问题的出现:
- 脏读
- 幻读
- 不可重复读
- 丢失修改
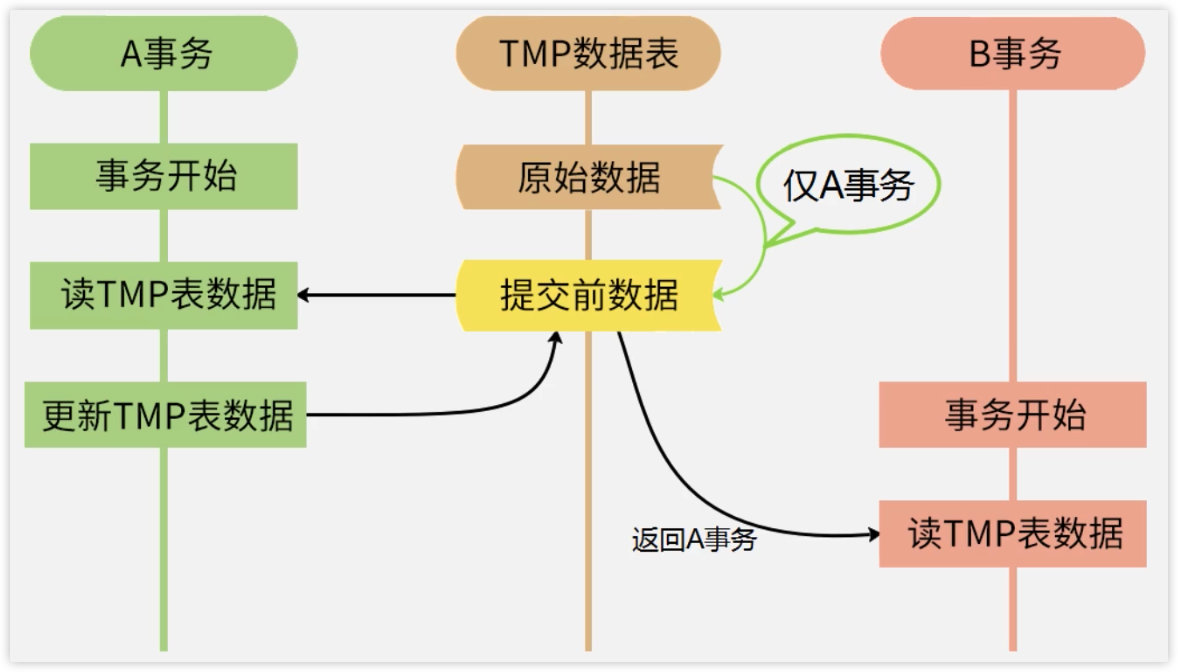
脏读场景
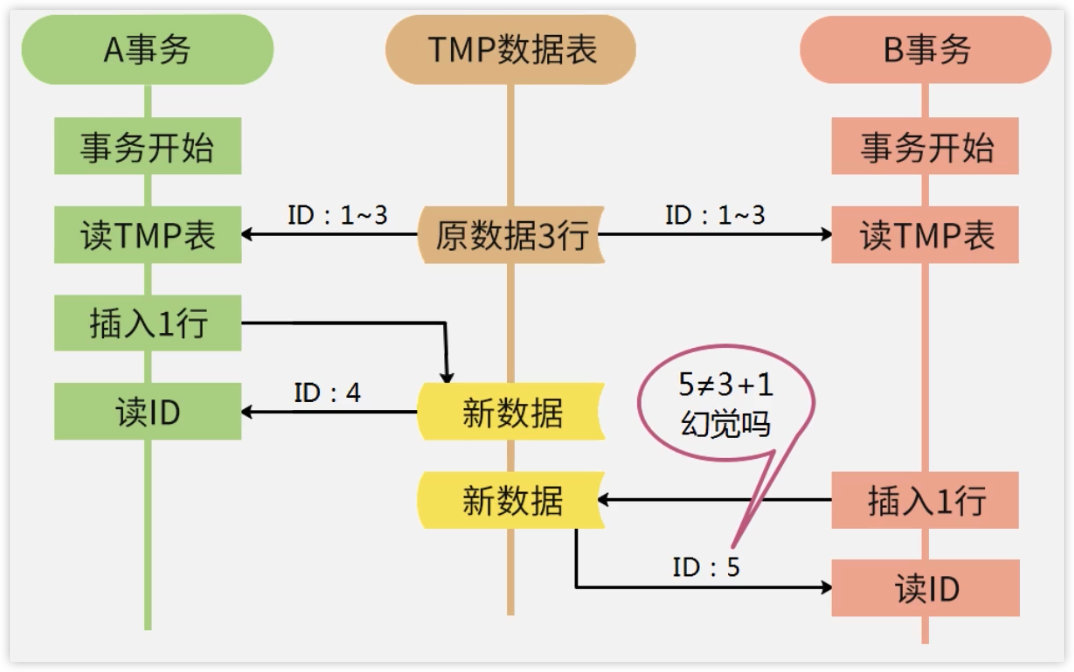
幻读场景
不可重复读场景:两次读到的数据不一致。
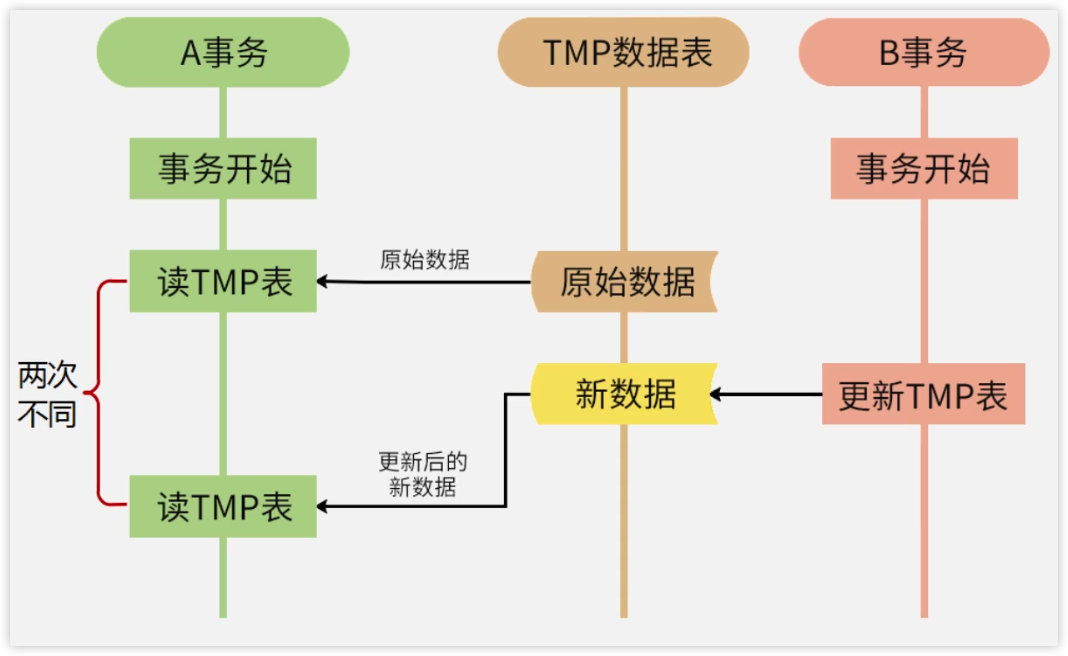
丢失修改
事务隔离
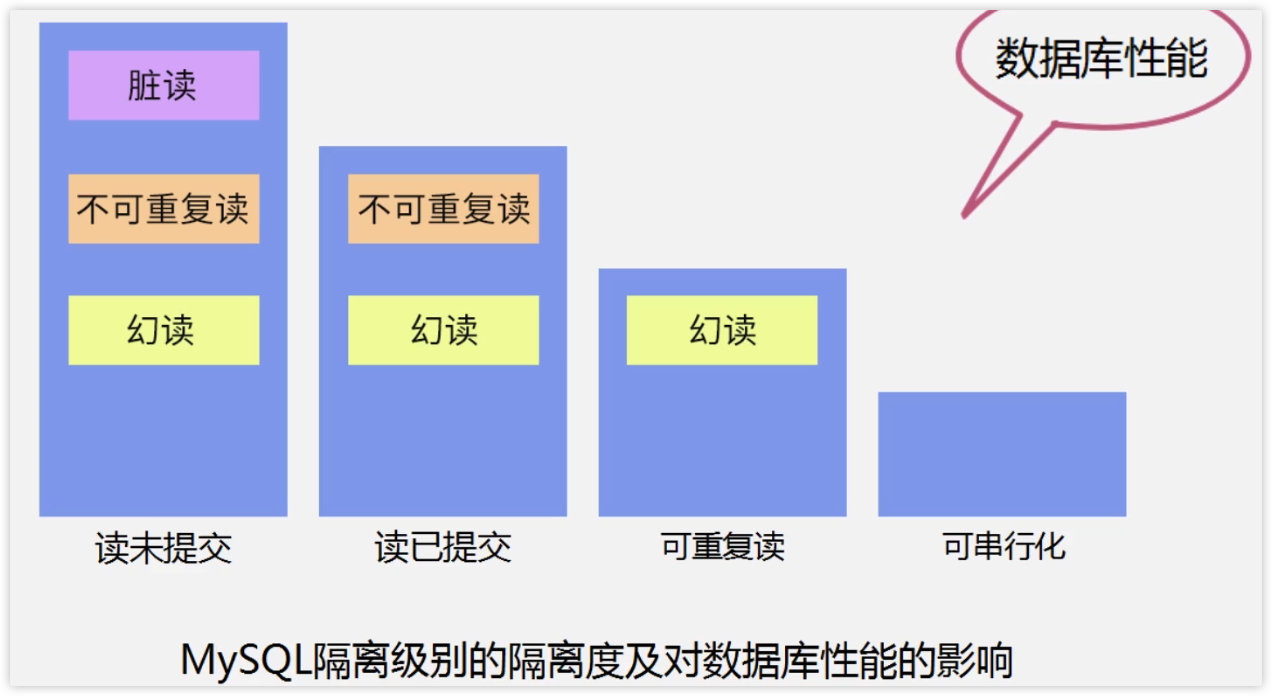
事务隔离用于解决事务并发中产生的 4 类问题,事务隔离级别有 4 种,从低到高:
- 读未提交
- 读已提交
- 可重复读 * (常用)
- 可串行化
不同隔离级别对性能影响不同:
性能优化 *
在并发场景下,事务会影响数据库的并发性能,因此在实际开发中,要注意排查事务使用的合理性。